•
20-minutę czytania
•


Ta lista kontrolna opisuje wszystkie nakrętki i śruby audytu technicznego zakładu, od teorii do praktyki.
Dowiesz się, jakie istnieją pliki techniczne, dlaczego występują problemy z SEO oraz jak je naprawiać i zapobiegać im w przyszłości, aby zawsze być bezpiecznym przed nagłymi spadkami w rankingu .
Po drodze pokażę kilka narzędzi do audytu SEO, zarówno popularnych, jak i mało znanych, aby bezproblemowo przeprowadzić techniczny audyt witryny.
Liczba kroków na technicznej liście kontrolnej SEO będzie zależała od celów i rodzaju witryn, które zamierzasz zbadać. Chcieliśmy, aby ta lista kontrolna była uniwersalna i obejmowała wszystkie ważne etapy technicznego audytu SEO.
1. Uzyskaj dostęp do analityki witryny i narzędzi dla webmasterów
Aby przeprowadzić audyt techniczny swojej witryny, będziesz potrzebować narzędzi analitycznych i narzędzi dla webmasterów, i dobrze, jeśli masz je już skonfigurowane w swojej witrynie. Dzięki Google Analytics , Google Search Console , Bing Webmaster Tools i tym podobnym masz już dużą porcję danych potrzebnych do podstawowego sprawdzenia witryny .
2. Sprawdź bezpieczeństwo domeny
Jeśli przeprowadzasz audyt istniejącej witryny, która spadła z rankingów, przede wszystkim wyklucz możliwość, że domena podlega jakimkolwiek sankcjom wyszukiwarek.
Aby to zrobić, skonsultuj się z Google Search Console. Jeśli Twoja witryna została ukarana za nielegalne tworzenie linków lub została zaatakowana przez hakerów, zobaczysz odpowiednie powiadomienie na karcie Bezpieczeństwo i działania ręczne w konsoli. Zanim przejdziesz do dalszego audytu technicznego swojej witryny, zapoznaj się z ostrzeżeniem widocznym na tej karcie. Jeśli potrzebujesz pomocy, zapoznaj się z naszym przewodnikiem, jak radzić sobie z karami ręcznymi i algo .
Jeśli przeprowadzasz audyt zupełnie nowej witryny, która ma zostać uruchomiona, upewnij się, że Twoja domena nie jest zagrożona. Aby uzyskać szczegółowe informacje, zapoznaj się z naszymi przewodnikami, jak wybrać wygasłe domeny i jak nie dać się uwięzić w piaskownicy Google podczas uruchamiania witryny.
Teraz, gdy prace przygotowawcze mamy już za sobą, przejdźmy krok po kroku do technicznego audytu SEO Twojej witryny.
Ogólnie rzecz biorąc, istnieją dwa rodzaje problemów z indeksowaniem. Jednym z nich jest sytuacja, w której adres URL nie jest indeksowany, mimo że powinien. Drugi to indeksowanie adresu URL, chociaż nie powinno tak być. Jak więc sprawdzić liczbę zaindeksowanych adresów URL witryny?
Aby zobaczyć, jaka część Twojej witryny faktycznie znalazła się w indeksie wyszukiwania, sprawdź raport Zasięg w Google Search Console . Raport pokazuje, ile Twoich stron jest obecnie zaindeksowanych, ile wykluczonych oraz jakie są niektóre problemy z indeksowaniem w Twojej witrynie.
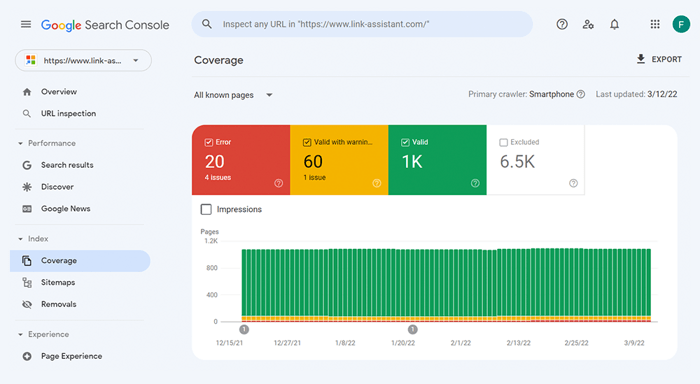

Pierwszy rodzaj problemów z indeksowaniem jest zwykle oznaczany jako błąd. Błędy indeksowania występują, gdy poprosisz Google o zindeksowanie strony, ale zostanie ona zablokowana. Na przykład strona została dodana do mapy witryny, ale jest oznaczona tagiem noindex lub zablokowana przez plik robots.txt.
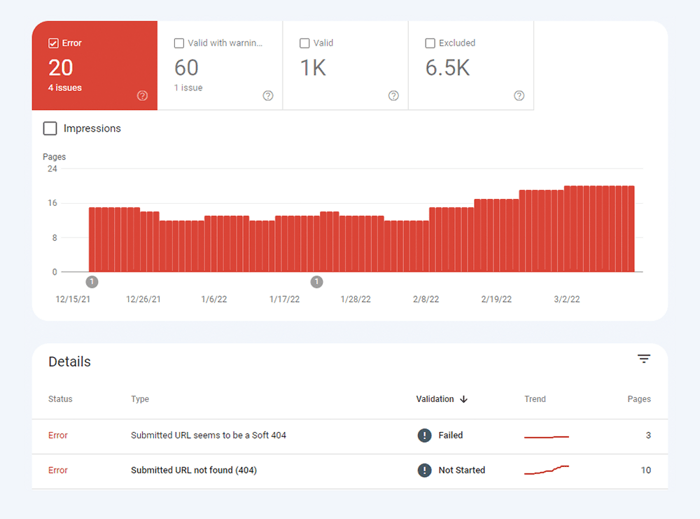
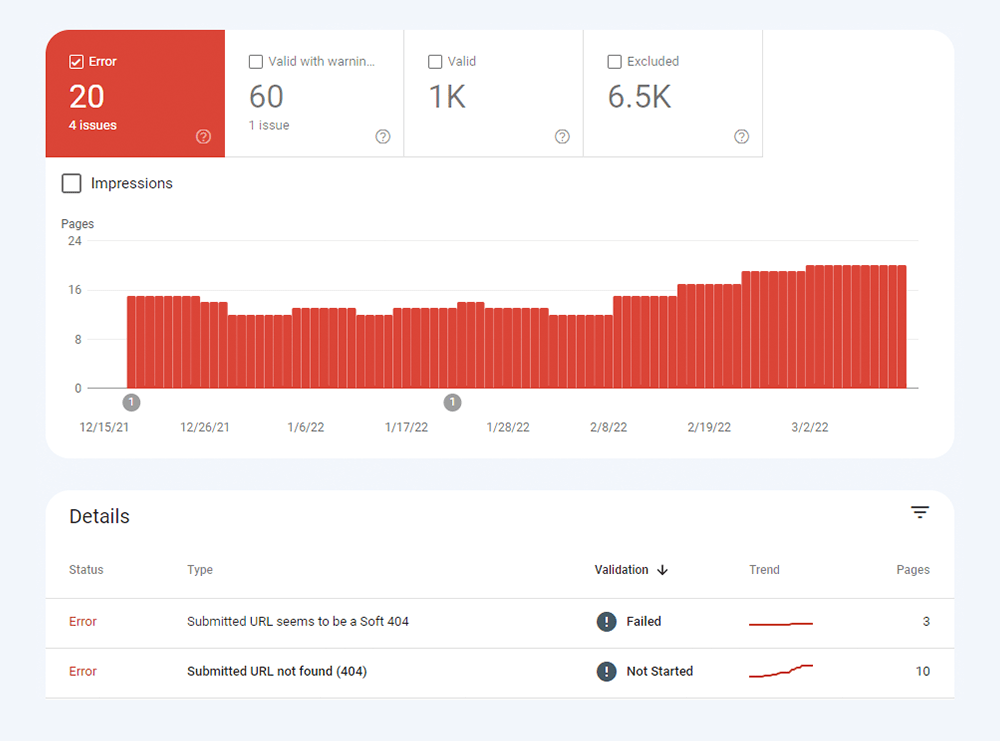
Innym rodzajem problemów z indeksowaniem jest sytuacja, gdy strona jest indeksowana, ale Google nie ma pewności, czy miała ona zostać zindeksowana. W Google Search Console strony te są zwykle oznaczane jako Prawidłowe z ostrzeżeniami .

W przypadku pojedynczej strony uruchom narzędzie do sprawdzania adresów URL w Search Console, aby sprawdzić, jak widzi ją robot wyszukiwania Google. Uderz w odpowiednią kartę lub wklej pełny adres URL w pasku wyszukiwania u góry, a pobierze wszystkie informacje o adresie URL, sposobie, w jaki został zeskanowany ostatnim razem przez bota wyszukiwania.
Następnie możesz kliknąć Testuj adres URL na żywo i zobaczyć jeszcze więcej szczegółów na temat strony: kod odpowiedzi, tagi HTML, zrzut ekranu pierwszego ekranu itp.
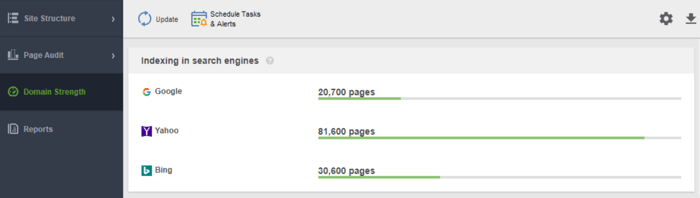
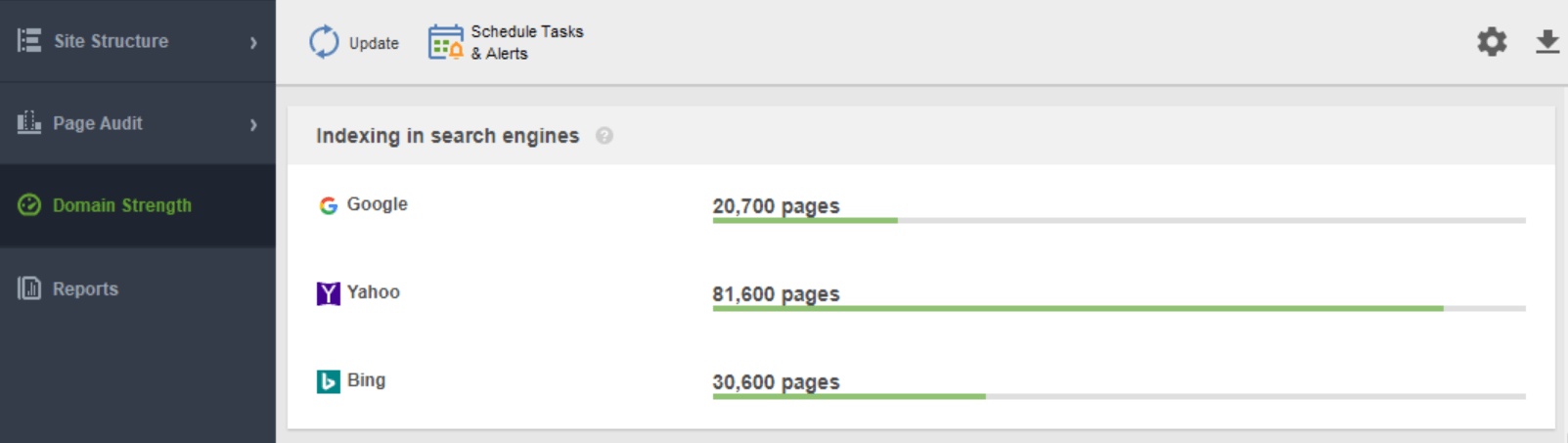
Kolejnym narzędziem do monitorowania indeksowania jest WebSite Auditor . Uruchom oprogramowanie i wklej adres URL swojej witryny, aby utworzyć nowy projekt i przejść do audytu witryny. Po zakończeniu indeksowania zobaczysz wszystkie problemy i ostrzeżenia w module Site Structure programu WebSite Auditor. W raporcie Siła domeny sprawdź liczbę zaindeksowanych stron nie tylko w Google, ale także w innych wyszukiwarkach.
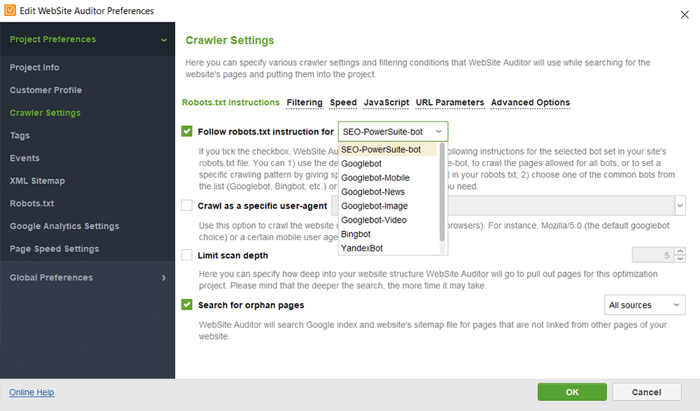
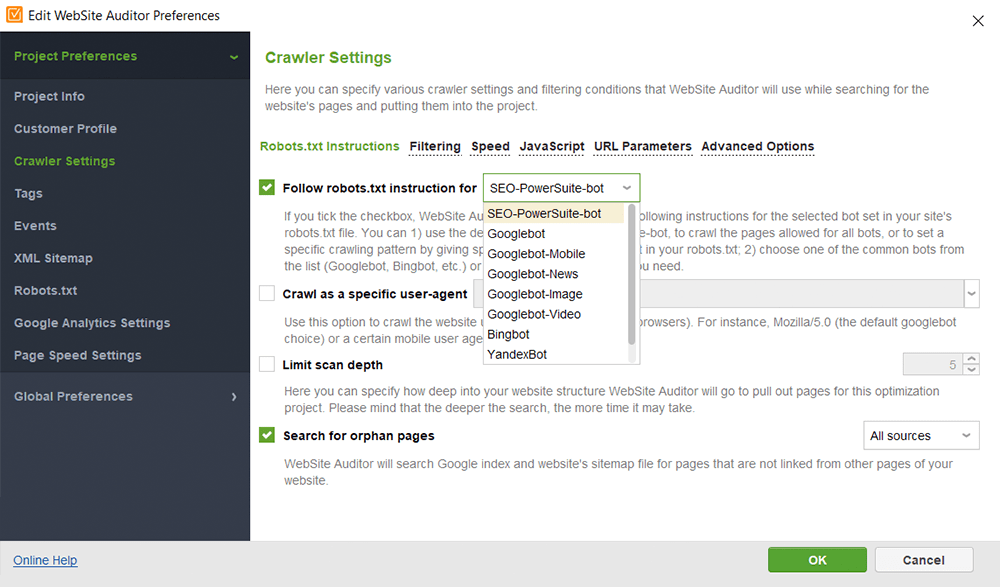
W WebSite Auditor możesz dostosować skanowanie witryny, wybierając innego bota wyszukiwania i określając ustawienia indeksowania. W preferencjach projektu pająka SEO zdefiniuj bota wyszukiwarki i konkretnego agenta użytkownika. Wybierz typy zasobów, które chcesz zbadać podczas indeksowania (lub odwrotnie, pomiń skanowanie). Możesz także poinstruować robota indeksującego, aby sprawdzał poddomeny i witryny chronione hasłem, ignorował specjalne parametry adresów URL i nie tylko.
Obejrzyj ten szczegółowy przewodnik wideo, aby dowiedzieć się, jak skonfigurować projekt i przeanalizować witryny internetowe.
Za każdym razem, gdy użytkownik lub robot wyszukujący wysyła żądanie do serwera zawierającego dane strony, w pliku dziennika rejestrowany jest wpis na ten temat. To najbardziej poprawne i aktualne informacje o robotach indeksujących i użytkownikach Twojej witryny, błędach indeksowania, marnowaniu budżetu indeksowania, tymczasowych przekierowaniach i nie tylko. Ponieważ ręczna analiza plików dziennika może być trudna, potrzebny będzie program do analizy plików dziennika .
Bez względu na to, z którego narzędzia zdecydujesz się skorzystać, liczba zaindeksowanych stron powinna być zbliżona do rzeczywistej liczby stron w Twojej witrynie.
A teraz przejdźmy do sposobu kontrolowania przeszukiwania i indeksowania witryny.
Domyślnie, jeśli nie masz żadnych technicznych plików SEO z elementami sterującymi indeksowaniem, roboty wyszukujące będą nadal odwiedzać Twoją witrynę i indeksować ją tak, jak jest. Jednak pliki techniczne pozwalają kontrolować sposób, w jaki roboty wyszukiwarek przemierzają i indeksują Twoje strony, dlatego są wysoce zalecane, jeśli Twoja witryna jest duża. Poniżej znajduje się kilka sposobów modyfikowania reguł indeksowania/indeksowania:
Jak więc przyspieszyć indeksowanie Twojej witryny przez Google za pomocą każdego z nich?
Mapa witryny to techniczny plik SEO zawierający listę wszystkich stron, filmów i innych zasobów w Twojej witrynie, a także relacje między nimi. Plik mówi wyszukiwarkom, jak wydajniej indeksować Twoją witrynę i odgrywa kluczową rolę w dostępności Twojej witryny.
Witryna potrzebuje mapy witryny, gdy:
Istnieją różne rodzaje map witryn, które możesz chcieć dodać do swojej witryny, w zależności głównie od typu witryny, którą zarządzasz.
Mapa witryny HTML jest przeznaczona dla czytelników i znajduje się na dole witryny. Ma jednak niewielką wartość SEO. Mapa witryny w formacie HTML pokazuje ludziom główną nawigację i zazwyczaj powiela linki w nagłówkach witryny. W międzyczasie mapy witryn HTML można wykorzystać do zwiększenia dostępności stron, które nie są zawarte w menu głównym.
W przeciwieństwie do map witryn HTML, mapy witryn XML są czytelne dla maszyn dzięki specjalnej składni. Mapa witryny XML znajduje się w domenie głównej, na przykład https://www.link-assistant.com/sitemap.xml. W dalszej części omówimy wymagania i znaczniki do tworzenia prawidłowej mapy witryny XML.
Jest to alternatywny rodzaj mapy witryny dostępny dla robotów wyszukiwarek. Mapa witryny TXT zawiera po prostu listę wszystkich adresów URL witryn, bez podawania żadnych innych informacji o zawartości.
Ten typ map witryn jest pomocny w przypadku obszernych bibliotek obrazów i obrazów o dużych rozmiarach, aby pomóc im w rankingu w Wyszukiwarce grafiki Google. W mapie witryny z obrazami można podać dodatkowe informacje o obrazie, takie jak lokalizacja geograficzna, tytuł i licencja. Na każdej stronie można umieścić do 1000 obrazów.
Mapy witryn wideo są potrzebne do treści wideo hostowanych na Twoich stronach, aby poprawić ich pozycję w wyszukiwarce Google Video. Chociaż Google zaleca korzystanie z danych strukturalnych w przypadku filmów, mapa witryny może być również przydatna, zwłaszcza gdy na stronie znajduje się dużo treści wideo. W mapie witryny wideo można dodać dodatkowe informacje o filmie wideo, takie jak tytuły, opis, czas trwania, miniatury, a nawet to, czy jest odpowiedni dla całej rodziny w przypadku Safe Search.
W przypadku witryn wielojęzycznych i wieloregionalnych wyszukiwarki mogą określić, która wersja językowa ma być wyświetlana w określonej lokalizacji, na kilka sposobów. Hreflangi to jeden z kilku sposobów obsługi zlokalizowanych stron i możesz do tego użyć specjalnej mapy witryny hreflang. Mapa witryny hreflang zawiera sam adres URL wraz z jego elementem podrzędnym wskazującym kod języka/regionu strony.
Jeśli prowadzisz bloga z wiadomościami, dodanie mapy witryny News-XML może pozytywnie wpłynąć na Twoje rankingi w Google News. Tutaj dodajesz informacje o tytule, języku i dacie publikacji. Do mapy witryny wiadomości można dodać maksymalnie 1000 adresów URL. Adresy URL nie powinny być starsze niż dwa dni, po czym można je usunąć, ale pozostaną w indeksie przez 30 dni.
Jeśli Twoja witryna zawiera kanał RSS, możesz przesłać adres URL kanału jako mapę witryny. Większość oprogramowania do blogów umożliwia tworzenie kanałów, ale te informacje są przydatne tylko do szybkiego wyszukiwania ostatnich adresów URL.
Obecnie najczęściej używane są mapy witryn XML, więc krótko omówmy główne wymagania dotyczące generowania map witryn XML:
Mapa witryny XML jest zakodowana w UTF-8 i zawiera obowiązkowe tagi dla elementu XML:
Będzie wyglądał prosty przykład mapy witryny XML z jednym wpisem
Istnieją opcjonalne tagi wskazujące priorytet i częstotliwość indeksowania strony — <priority>, <changefreq> (obecnie Google je ignoruje) i wartość <lastmod> , jeśli jest dokładna (na przykład w porównaniu z ostatnią modyfikacją na stronie) .
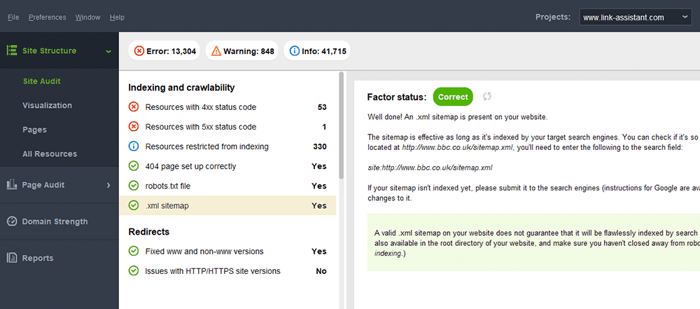
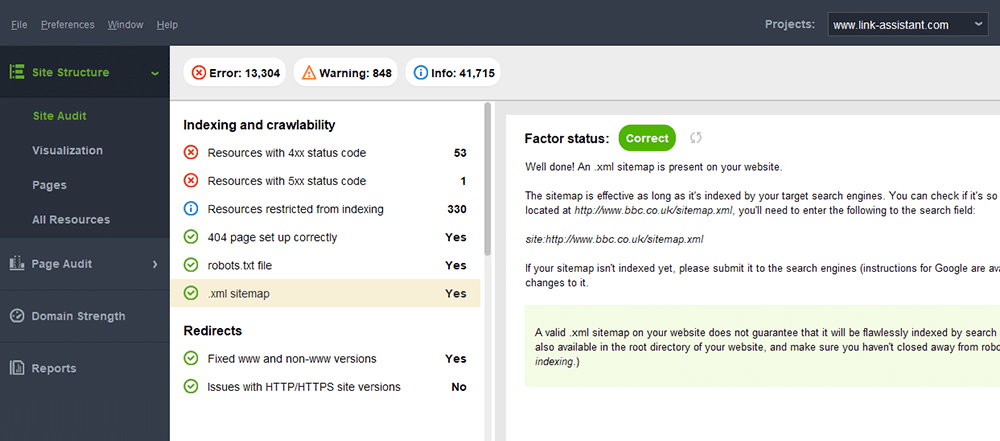
Typowym błędem związanym z mapami witryn jest brak prawidłowej mapy witryny XML w dużej domenie. Możesz sprawdzić obecność mapy witryny na swojej stronie za pomocą WebSite Auditor . Znajdź wyniki w sekcji Audyt witryny > Indeksowanie i możliwość indeksowania .
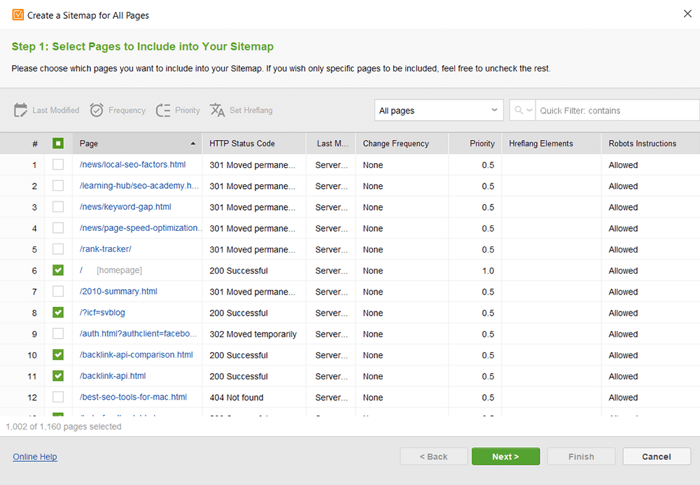
Jeśli nie masz mapy witryny, powinieneś natychmiast ją utworzyć. Możesz szybkowygenerować mapę witryny za pomocą narzędzi witryny WebSite Auditor po przejściu do sekcji Strony .
I poinformuj Google o swojej mapie witryny. Aby to zrobić, możesz
Faktem jest, że posiadanie mapy witryny w witrynie nie gwarantuje, że wszystkie strony zostaną zindeksowane, a nawet zindeksowane . Istnieje kilka innych technicznych zasobów SEO, których celem jest poprawa indeksacji witryny. Przejrzymy je w kolejnych krokach.
Plik robots.txt informuje wyszukiwarki, do których adresów URL robot indeksujący może uzyskać dostęp w Twojej witrynie. Ten plik służy do unikania przeciążenia serwera żądaniami i zarządzania ruchem związanym z indeksowaniem . Plik jest zwykle używany do:
Robots.txt jest umieszczany w katalogu głównym domeny, a każda subdomena musi mieć osobny plik. Pamiętaj, aby nie przekraczał 500kB i odpowiadał kodem 200.
Plik robots.txt ma również swoją składnię z regułami Zezwalaj i Disallow :
Różne wyszukiwarki mogą w różny sposób postępować zgodnie z dyrektywami. Na przykład Google zrezygnował z używania dyrektyw noindex, crawl-delay i nofollow z pliku robots.txt. Poza tym istnieją specjalne roboty indeksujące, takie jak Googlebot-Image, Bingbot, Baiduspider-image, DuckDuckBot, AhrefsBot itp. Możesz więc zdefiniować reguły dla wszystkich botów wyszukiwania lub osobne reguły tylko dla niektórych z nich.
Pisanie instrukcji dla pliku robots.txt może być dość trudne, więc zasadą jest mniej instrukcji i więcej zdrowego rozsądku. Poniżej znajduje się kilka przykładów ustawienia instrukcji pliku robots.txt.
Pełny dostęp do domeny. W takim przypadku reguła zakazu nie jest wypełniona.
Pełne zablokowanie hosta.
Instrukcja zabrania indeksowania wszystkich adresów URL zaczynających się od przesyłania po nazwie domeny.
Instrukcja uniemożliwia robotowi Googlebot-News indeksowanie wszystkich plików gif w folderze news.
Pamiętaj, że jeśli ustawisz jakąś ogólną instrukcję A dla wszystkich wyszukiwarek i jedną wąską instrukcję B dla konkretnego bota, to określony bot może postępować zgodnie z wąską instrukcją i wykonywać wszystkie inne ogólne zasady ustawione domyślnie dla bota, ponieważ nie będzie ograniczona regułą A. Na przykład, jak w poniższej regule:
Tutaj AdsBot-Google-Mobile może indeksować pliki w folderze tmp pomimo instrukcji z symbolem wieloznacznym *.
Jednym z typowych zastosowań plików robots.txt jest wskazanie lokalizacji mapy witryny. W takim przypadku nie musisz wspominać o klientach użytkownika, ponieważ reguła dotyczy wszystkich robotów indeksujących. Mapa witryny powinna zaczynać się od dużej litery S (pamiętaj, że w pliku robots.txt rozróżniana jest wielkość liter), a adres URL musi być bezwzględny (tj. powinien zaczynać się od pełnej nazwy domeny).
Pamiętaj, że jeśli ustawisz sprzeczne instrukcje, roboty indeksujące będą dawać pierwszeństwo dłuższej instrukcji. Na przykład:
Tutaj skrypt /admin/js/global.js będzie nadal dozwolony dla robotów indeksujących pomimo pierwszej instrukcji. Wszystkie inne pliki w folderze administratora nadal będą niedozwolone.
Możesz sprawdzić dostępność pliku robots.txt w WebSite Auditor. Pozwala również wygenerować plik za pomocą narzędzia generatora robots.txt , z dalszym zapisywaniem lub przesyłaniem go bezpośrednio na stronę internetową przez FTP.
Pamiętaj, że plik robots.txt jest publicznie dostępny i może wyświetlać niektóre strony, zamiast je ukrywać. Jeśli chcesz ukryć niektóre foldery prywatne, zabezpiecz je hasłem.
Wreszcie plik robots.txt nie gwarantuje, że niedozwolona strona nie zostanie przeszukana ani zindeksowana . Zablokowanie indeksowania strony przez Google prawdopodobnie usunie ją z indeksu Google, jednak robot wyszukiwania nadal może indeksować stronę, kierując się niektórymi linkami zwrotnymi. Oto inny sposób na zablokowanie przeszukiwania i indeksowania strony — metaroboty.
Metatagi robotów to świetny sposóbna poinstruowanie robotów indeksujących, jak traktować poszczególne strony. Meta tagi robots są dodawane do sekcji <head> Twojej strony HTML, dlatego instrukcje dotyczą całej strony. Możesz utworzyć wiele instrukcji, łącząc dyrektywy meta tagów robots z przecinkami lub używając wielu metatagów. Może to wyglądać tak:
Możesz na przykład określić meta tagi robots dla różnych robotów indeksujących
Google rozumie takie tagi jak:
Przeciwne tagi index/follow/archiwum zastępują odpowiednie dyrektywy zakazujące. Istnieją inne tagi informujące o tym, jak strona może wyglądać w wynikach wyszukiwania, takie jak snippet / nosnippet / notranslate / nopagereadaloud / noimageindex .
Jeśli użyjesz innych tagów ważnych dla innych wyszukiwarek, ale nieznanych Google, Googlebot po prostu je zignoruje.
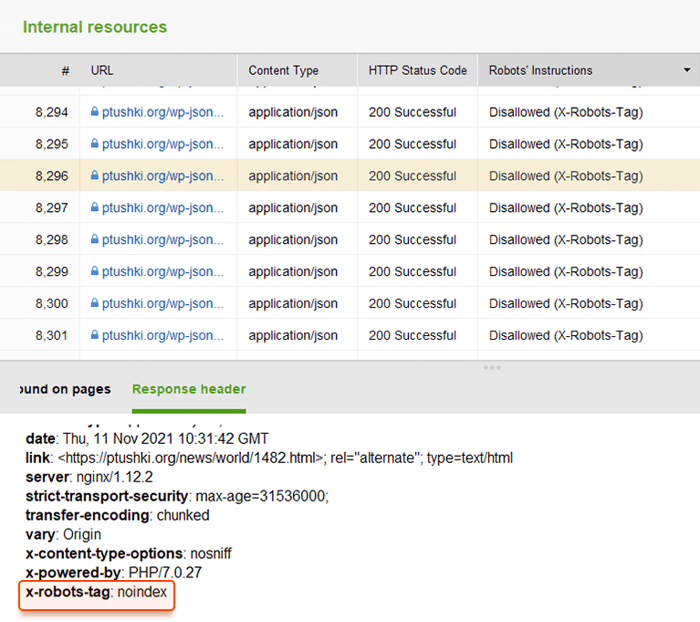
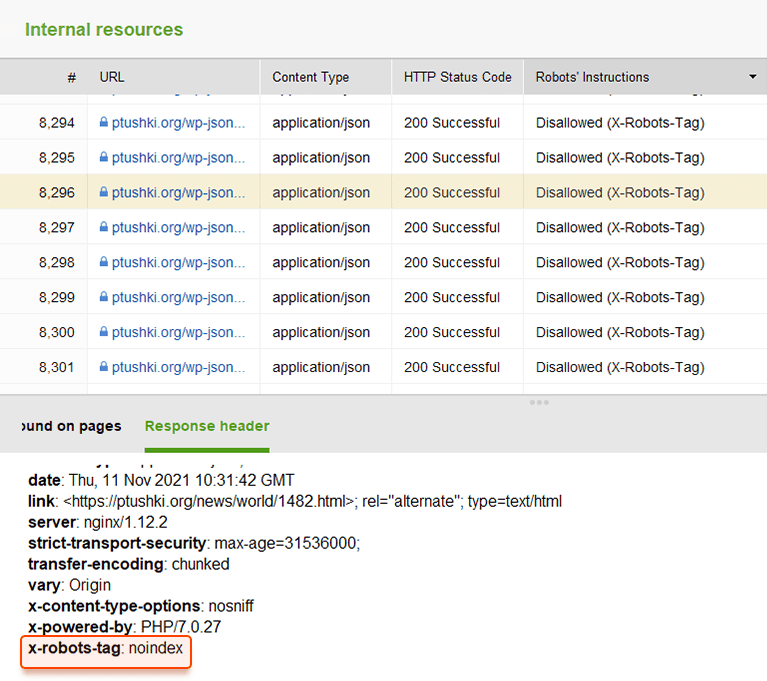
Zamiast metatagów możesz użyć nagłówka odpowiedzi dla zasobów innych niż HTML , takich jak pliki PDF, pliki wideo i obrazy. Ustaw zwracanie w odpowiedzi nagłówka X-Robots-Tag z wartością noindex lub none.
Możesz także użyć kombinacji dyrektyw , aby określić, jak fragment będzie wyglądał w wynikach wyszukiwania, na przykład max-image-preview: [setting] lub nosnippet lub max-snippet: [number] itd.
Możesz dodać X-Robots-Tag do odpowiedzi HTTP witryny za pomocą plików konfiguracyjnych oprogramowania serwera sieciowego Twojej witryny. Twoje dyrektywy indeksowania mogą być stosowane globalnie w całej witrynie dla wszystkich plików, a także dla poszczególnych plików, jeśli zdefiniujesz ich dokładne nazwy.
Możesz szybko przejrzeć wszystkie instrukcje dotyczące robotów za pomocą WebSite Auditor . Przejdź do pozycji Struktura witryny > Wszystkie zasoby > Zasoby wewnętrzne i sprawdź kolumnę Instrukcje dotyczące robotów . Tutaj znajdziesz niedozwolone strony i zastosowaną metodę, plik robots.txt, metatagi lub X-Robots-tag.
Serwer hostujący witrynę generuje kod stanu HTTP, odpowiadając na żądanie klienta, przeglądarki lub robota. Jeśli serwer odpowie kodem stanu 2xx, otrzymana treść może zostać uwzględniona w indeksowaniu. Inne odpowiedzi od 3xx do 5xx wskazują na problem z renderowaniem treści. Oto kilka znaczeń odpowiedzi kodu stanu HTTP:
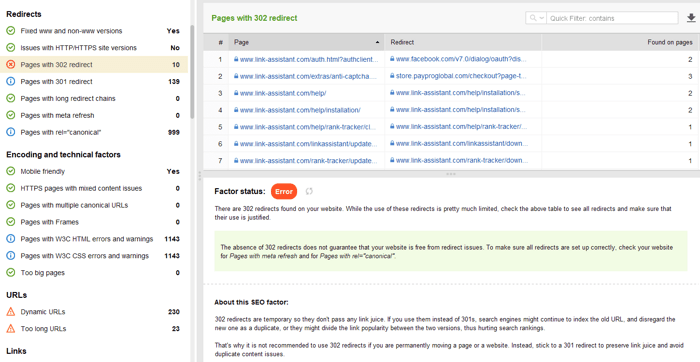
Przekierowania 301 są używane, gdy:
Tymczasowe przekierowanie 302
Tymczasowe przekierowanie 302 powinno być używane tylko na stronach tymczasowych. Na przykład, gdy przeprojektowujesz stronę lub testujesz nową stronę i zbierasz opinie, ale nie chcesz, aby adres URL spadł z rankingu.
304, aby sprawdzić pamięć podręczną
Kod odpowiedzi 304 jest obsługiwany we wszystkich najpopularniejszych wyszukiwarkach, takich jak Google, Bing, Baidu, Yandex itp. Prawidłowa konfiguracja kodu odpowiedzi 304 pomaga botowi zrozumieć, co zmieniło się na stronie od ostatniego indeksowania. Bot wysyła żądanie HTTP If-Modified-Since. Jeśli od daty ostatniego indeksowania nie zostaną wykryte żadne zmiany, robot wyszukujący nie musi ponownie indeksować strony. Dla użytkownika oznacza to, że strona nie zostanie w pełni przeładowana, a jej zawartość zostanie pobrana z pamięci podręcznej przeglądarki.
Kod 304 pomaga również:
Ważne jest, aby sprawdzić buforowanie nie tylko zawartości strony, ale także plików statycznych, takich jak obrazy czy style CSS. Istnieją specjalne narzędzia, takie jak to , do sprawdzania kodu odpowiedzi 304.


Najczęściej problemy z kodem odpowiedzi serwera pojawiają się, gdy roboty podążają za wewnętrznymi i zewnętrznymi linkami do usuniętych lub przeniesionych stron, uzyskując odpowiedzi 3xx i 4xx.
Błąd 404 oznacza, że strona jest niedostępna, a serwer wysyła do przeglądarki poprawny kod stanu HTTP — 404 Not Found.
Istnieją jednak miękkie błędy 404 , gdy serwer wysyła kod odpowiedzi 200 OK, ale Google uważa, że powinien to być 404. Może się tak zdarzyć, ponieważ:
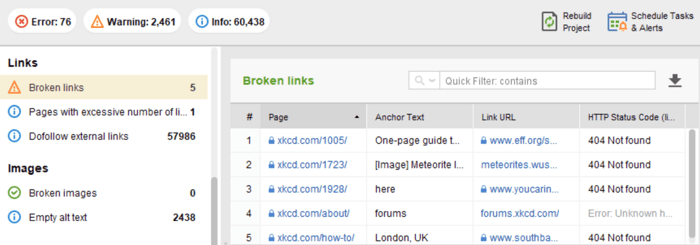
W module Audyt witryny WebSite Auditor przejrzyj zasoby z kodem odpowiedzi 4xx, 5xx na karcie Indeksowanie i indeksowanie oraz oddzielną sekcję dotyczącą niedziałających linków na karcie Łącza .
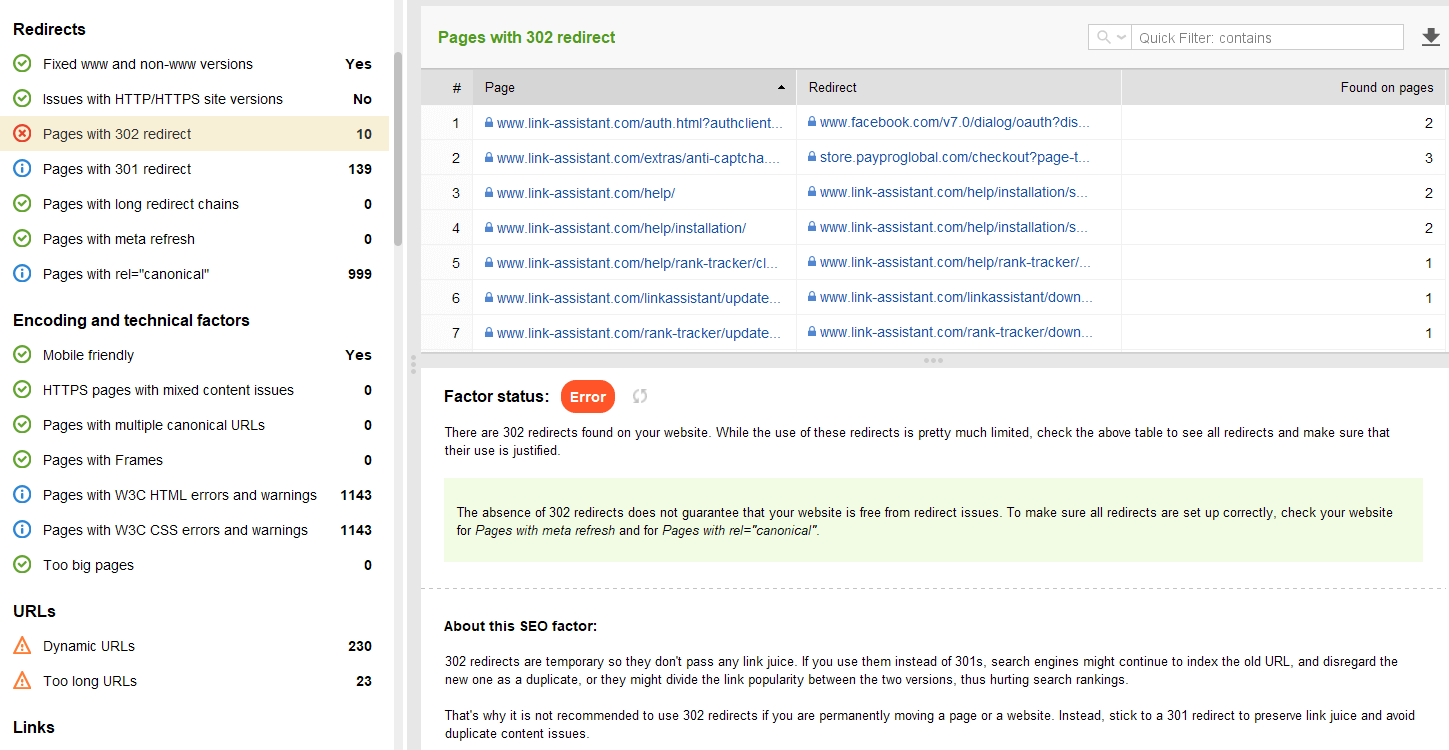
Niektóre inne typowe problemy z przekierowaniami związane z odpowiedziami 301/302:
Możesz przejrzeć wszystkie strony z przekierowaniami 301 i 302 w sekcji Audyt witryny > Przekierowania w WebSite Auditor.
Powielanie może stać się poważnym problemem podczas indeksowania witryny. Jeśli Google znajdzie zduplikowane adresy URL , zadecyduje, która z nich jest stroną główną i będzie ją indeksować częściej, podczas gdy duplikaty będą indeksowane rzadziej i mogą w ogóle wypaść z indeksu wyszukiwania. Pewnym rozwiązaniem jest wskazanie jednej ze zduplikowanych stron jako kanonicznej, czyli głównej. Można to zrobić za pomocą atrybutu rel=”canonical” , umieszczanego w kodzie HTML strony lub odpowiedziach nagłówka HTTP witryny.
Google używa stron kanonicznych do oceny treści i jakości, a najczęściej wyniki wyszukiwania prowadzą do stron kanonicznych, chyba że wyszukiwarki wyraźnie stwierdzą, że jakaś strona niekanoniczna jest bardziej odpowiednia dla użytkownika (na przykład jest to użytkownik mobilny lub wyszukiwarka w określonej lokalizacji).
Zatem kanonizacja odpowiednich stron pomaga:
Zduplikowane problemy oznaczają, że identyczna lub podobna treść pojawia się pod kilkoma adresami URL. Dość często duplikaty pojawiają się automatycznie z powodu technicznej obsługi danych na stronie internetowej.
Niektóre systemy CMS mogą automatycznie generować zduplikowane problemy z powodu niewłaściwych ustawień. Na przykład w różnych katalogach witryn można wygenerować wiele adresów URL, które są duplikatami:
Podział na strony może również powodować problemy z powielaniem, jeśli zostanie nieprawidłowo zaimplementowany. Na przykład adresy URL strony kategorii i strony 1 zawierają tę samą treść i dlatego są traktowane jako duplikaty. Taka kombinacja nie powinna istnieć lub strona kategorii powinna być oznaczona jako kanoniczna.
Wyniki sortowania i filtrowania mogą być reprezentowane jako duplikaty. Dzieje się tak, gdy witryna tworzy dynamiczne adresy URL do wyszukiwania lub filtrowania zapytań. Otrzymasz parametry adresu URL , które reprezentują aliasy ciągów zapytań lub zmiennych adresu URL, są to części adresu URL, które występują po znaku zapytania.
Aby uniemożliwić Google indeksowanie wielu niemal identycznych stron, ustaw ignorowanie niektórych parametrów adresów URL. Aby to zrobić, uruchom Google Search Console i przejdź do Starsze narzędzia i raporty > Parametry adresu URL . Kliknij Edytuj po prawej stronie i powiedz Google, które parametry ma zignorować – reguła będzie obowiązywać w całej witrynie. Należy pamiętać, że Narzędzie parametrów jest przeznaczone dla zaawansowanych użytkowników, dlatego należy obchodzić się z nim dokładnie.
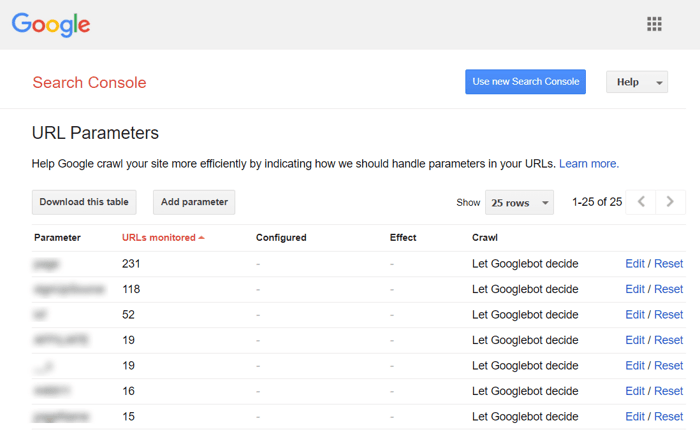
Problem powielania często występuje w witrynach e-commerce, które umożliwiają fasetową nawigację po filtrach , zawężając wyszukiwanie do trzech, czterech i więcej kryteriów. Oto przykład konfigurowania reguł indeksowania dla witryny e-commerce: przechowuj adresy URL z dłuższymi i węższymi wynikami wyszukiwania w określonym folderze i nie zezwalaj na to za pomocą reguły pliku robots.txt.
Problemy logiczne w strukturze witryny mogą powodować powielanie. Może się tak zdarzyć, gdy sprzedajesz produkty, a jeden produkt należy do różnych kategorii.
W takim przypadku produkty muszą być dostępne tylko za pośrednictwem jednego adresu URL. Adresy URL są uważane za pełne duplikaty i szkodzą SEO. Adres URL należy przypisać poprzez odpowiednie ustawienia CMS, generując unikalny pojedynczy adres URL dla jednej strony.
Częściowe powielanie często zdarza się w CMS WordPress, na przykład, gdy używane są tagi. Podczas gdy tagi poprawiają wyszukiwanie w witrynie i nawigację użytkownika, witryny WP generują strony tagów , które mogą pokrywać się z nazwami kategorii i przedstawiać podobną treść z podglądu fragmentu artykułu. Rozwiązaniem jest rozsądne używanie tagów, dodając tylko ograniczoną ich liczbę. Lub możesz dodać meta robots noindex dofollow na stronach tagów.
Jeśli zdecydujesz się udostępniać oddzielną mobilną wersję swojej witryny, a zwłaszcza generować strony AMP do wyszukiwania na urządzeniach mobilnych, możesz mieć duplikaty tego rodzaju.
Aby wskazać, że strona jest duplikatem, możesz użyć tagu <link> w sekcji head kodu HTML. W przypadku wersji mobilnych będzie to tag linku z wartością rel=“alternate”, taką jak ta:
To samo dotyczy stron AMP (które nie są trendem, ale nadal można je wykorzystać do renderowania wyników mobilnych). Zajrzyj do naszego przewodnika po implementacji stron AMP .
Istnieją różne sposoby prezentowania zlokalizowanych treści . Jeśli prezentujesz treść w różnych wariantach językowych/regionalnych i przetłumaczyłeś tylko nagłówek/stopkę/nawigację witryny, ale treść pozostaje w tym samym języku, adresy URL będą traktowane jako duplikaty.
Skonfiguruj wyświetlanie witryn wielojęzycznych i wieloregionalnych za pomocą tagów hreflang , dodając obsługiwane kody języka/regionu w kodzie HTML, kodach odpowiedzi HTTP lub w mapie witryny.
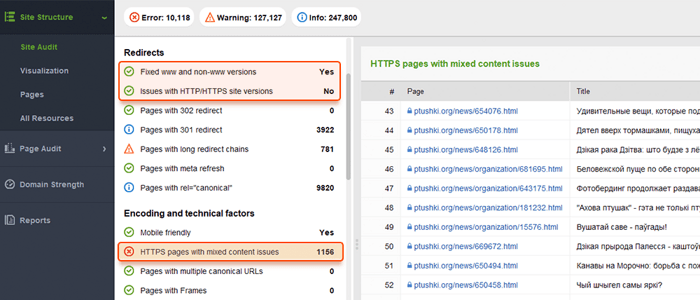
Strony internetowe są zwykle dostępne z „www” w nazwie domeny i bez niego. Ten problem jest dość powszechny, a ludzie odsyłają zarówno do wersji z www, jak i bez www. Naprawienie tego pomoże uniemożliwić wyszukiwarkom indeksowanie dwóch wersji witryny. Chociaż taka indeksacja nie spowoduje kary, ustawienie jednej wersji jako priorytetu jest najlepszą praktyką.
Google woli HTTPS niż HTTP, ponieważ bezpieczne szyfrowanie jest zdecydowanie zalecane w przypadku większości witryn (zwłaszcza podczas przeprowadzania transakcji i zbierania poufnych informacji o użytkownikach). Czasami webmasterzy napotykają problemy techniczne podczas instalowania certyfikatów SSL i konfigurowania wersji witryny HTTP/HTTPS. Jeśli witryna ma nieprawidłowy certyfikat SSL (niezaufany lub wygasł), większość przeglądarek internetowych uniemożliwi użytkownikom odwiedzenie Twojej witryny, powiadamiając ich o „niepewnym połączeniu”.
Jeśli wersje HTTP i HTTPS Twojej witryny nie są ustawione prawidłowo, obie mogą zostać zaindeksowane przez wyszukiwarki i spowodować problemy z powielaniem treści, które mogą obniżyć ranking Twojej witryny.
Jeśli Twoja witryna korzysta już z HTTPS (częściowo lub całkowicie), ważne jest wyeliminowanie typowych problemów z HTTPS w ramach audytu SEO witryny. W szczególności pamiętaj, abysprawdzić mieszaną zawartość w sekcji Audyt witryny > Kodowanie i czynniki techniczne .
Problemy z zawartością mieszaną pojawiają się, gdy strona skądinąd zabezpieczona ładuje część swojej zawartości (obrazy, filmy, skrypty, pliki CSS) przez niezabezpieczone połączenie HTTP. Osłabia to bezpieczeństwo i może uniemożliwić przeglądarkom załadowanie niezabezpieczonej treści lub nawet całej strony.
Aby uniknąć tych problemów, w pliku .htaccess możesz skonfigurować i wyświetlać podstawową wersję z przedrostkiem www lub bez przedrostka www dla swojej witryny. Ustaw także preferowaną domenę w Google Search Console i wskaż strony HTTPS jako kanoniczne.
Gdy uzyskasz pełną kontrolę nad zawartością swojej witryny, upewnij się, że nie ma zduplikowanych tytułów, nagłówków, opisów, obrazów itp. Aby uzyskać wskazówki dotyczące zduplikowanych treści w całej witrynie, zobacz sekcję On-page w Audycie witryny WebSite Auditor panel. Strony ze zduplikowanymi tytułami i tagami metaopisu prawdopodobnie również będą miały prawie identyczną treść.
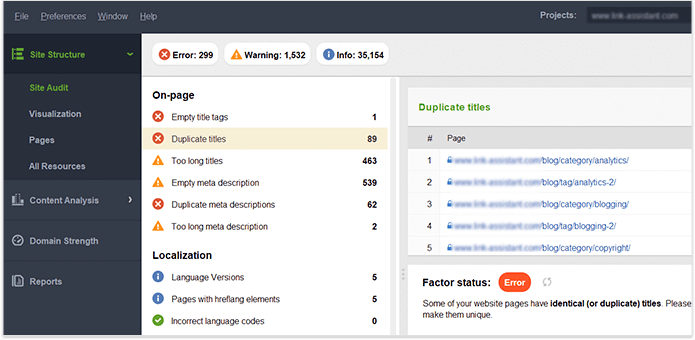
Podsumujmy, jak wykrywamy i rozwiązujemy problemy z indeksacją. Jeśli zastosowałeś się do wszystkich powyższych wskazówek, ale niektórych Twoich stron nadal nie ma w indeksie, oto podsumowanie, dlaczego tak się stało:
Dlaczego strona jest indeksowana, choć nie powinna?
Pamiętaj, że zablokowanie strony w pliku robots.txt i usunięcie jej z mapy witryny nie gwarantuje, że nie zostanie zaindeksowana. Możesz zapoznać się z naszym szczegółowym przewodnikiem , jak prawidłowo ograniczyć indeksowanie stron .
Płytka, logiczna architektura witryny jest ważna zarówno dla użytkowników, jak i robotów wyszukiwarek. Dobrze zaplanowana struktura witryny odgrywa również dużą rolę w jej rankingach, ponieważ:
Przeglądając strukturę swoich witryn i wewnętrzne linki, zwróć uwagę na następujące elementy.
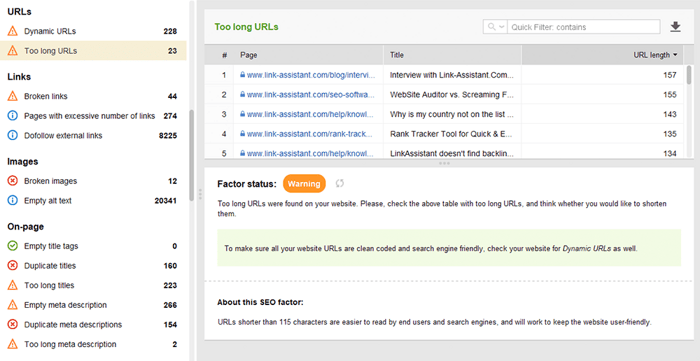
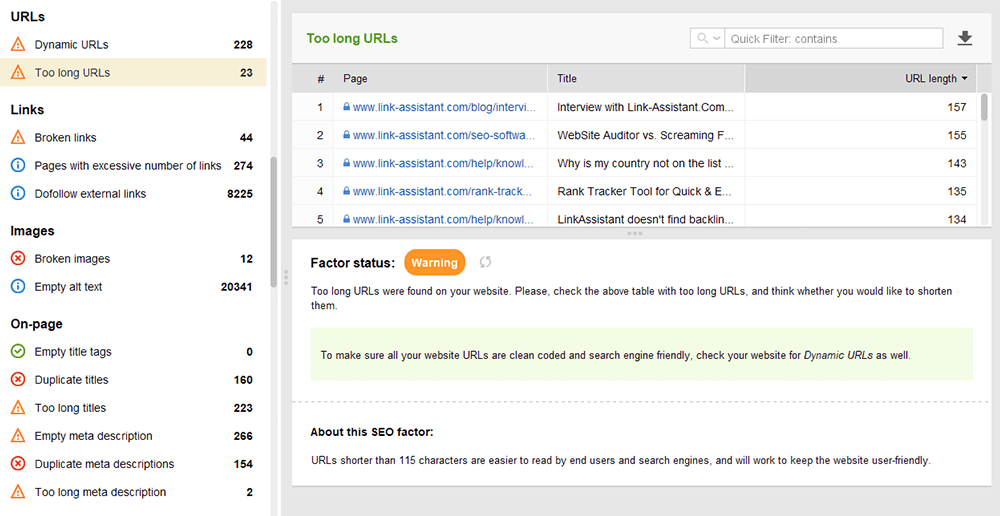
Zoptymalizowane adresy URL są kluczowe z dwóch powodów. Po pierwsze, jest to niewielki czynnik rankingowy dla Google. Po drugie, użytkownicy mogą być zdezorientowani przez zbyt długie lub niezdarne adresy URL. Myśląc o strukturze adresu URL, trzymaj się następujących najlepszych praktyk :
Możesz sprawdzić swoje adresy URL w sekcji Audyt witryny > Adresy URL w programie WebSite Auditor.
Istnieje wiele typów linków, niektóre z nich są mniej lub bardziej korzystne dla SEO Twojej witryny. Na przykład linki kontekstowe dofollow przekazują sok z linku i służą jako dodatkowy wskaźnik dla wyszukiwarek, czego dotyczy link. Linki są uważane za wysokiej jakości, gdy (dotyczy to zarówno linków wewnętrznych, jak i zewnętrznych):
Linki nawigacyjne w nagłówkach i paskach bocznych są również ważne dla SEO witryny, ponieważ pomagają użytkownikom i wyszukiwarkom poruszać się po stronach.
Inne linki mogą nie mieć żadnej wartości rankingowej, a nawet zaszkodzić władzom witryny. Na przykład masowe łącza wychodzące w całej witrynie w szablonach (których darmowe szablony WP miały dużo). Ten przewodnik po typach linków w SEO mówi, jak budować wartościowe linki we właściwy sposób.
Możesz użyć narzędzia WebSite Auditor , aby dokładnie zbadać wewnętrzne linki i ich jakość.
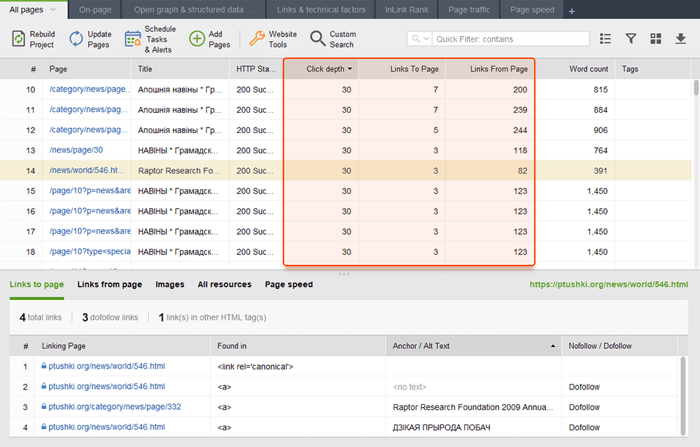
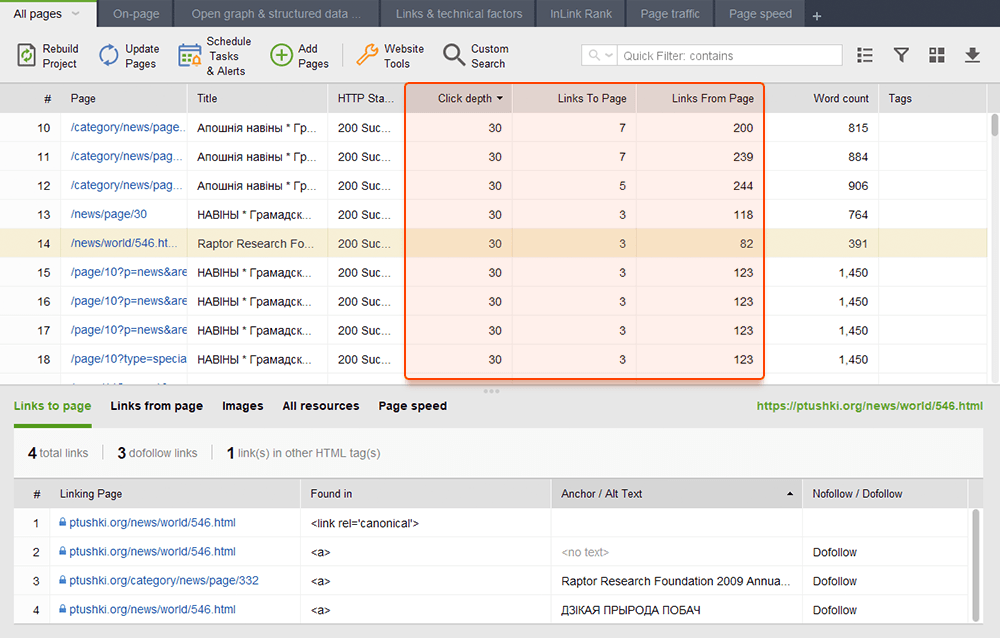
Strony osierocone to niepowiązane strony, które pozostają niezauważone i ostatecznie mogą wypaść z indeksu wyszukiwania. Aby znaleźć strony osierocone, przejdź do Audyt witryny > Wizualizacja i przejrzyj wizualną mapę witryny . Tutaj łatwo zobaczysz wszystkie niepowiązane strony i długie łańcuchy przekierowań (przekierowania 301 i 302 są zaznaczone na niebiesko).
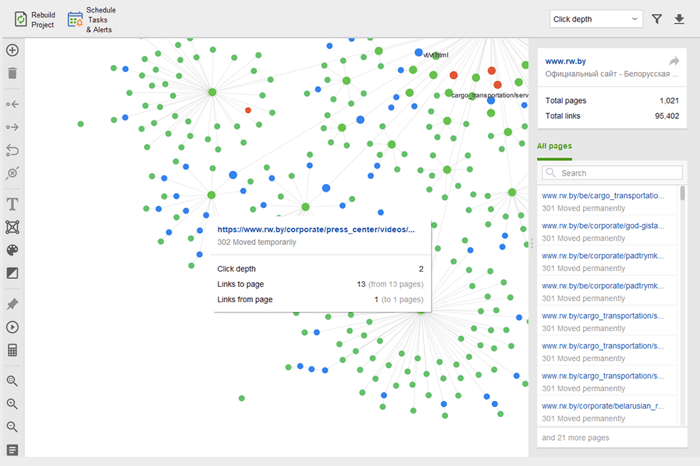
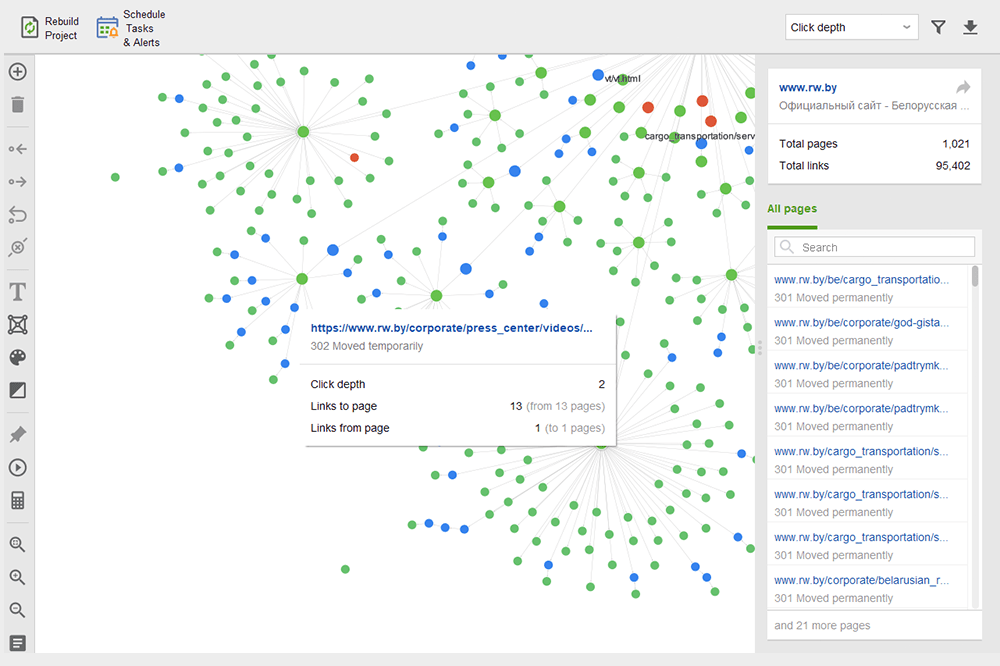
Możesz przejrzeć całą strukturę witryny, zbadać wagę jej głównych stron — sprawdzając odsłony (zintegrowane z Google Analytics), PageRank i sok z linków, które uzyskują z linków przychodzących i wychodzących. Możesz dodawać i usuwać linki oraz przebudowywać projekt, ponownie obliczając widoczność każdej strony.
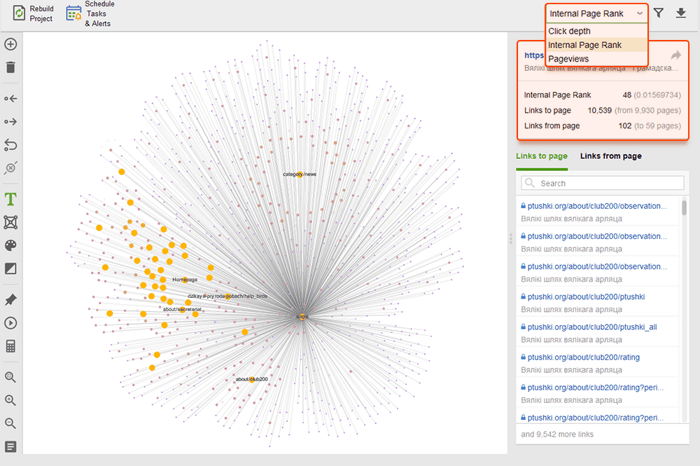
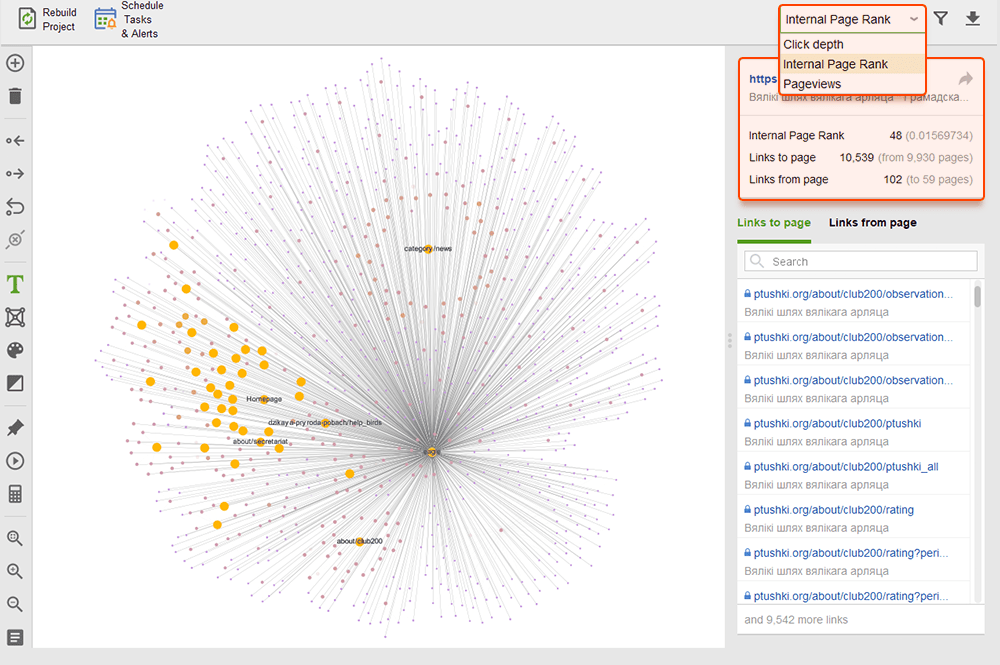
Podczas audytu linków wewnętrznych sprawdź głębokość kliknięć. Upewnij się, że ważne strony Twojej witryny znajdują się nie dalej niż trzy kliknięcia od strony głównej. Innym miejscem, w którym można sprawdzić głębokość kliknięć w programie WebSite Auditor, jest przejście do opcji Struktura witryny > Strony . Następnie posortuj adresy URL według głębokości kliknięć w kolejności malejącej, klikając dwukrotnie nagłówek kolumny.
Paginacja stron blogów jest niezbędna do wyszukiwania przez wyszukiwarki, chociaż zwiększa głębokość kliknięć. Użyj prostej struktury wraz z praktycznym wyszukiwaniem w witrynie, aby ułatwić użytkownikom znalezienie dowolnego zasobu.
Aby uzyskać więcej informacji, zapoznaj się z naszym szczegółowym przewodnikiem po paginacji przyjaznej dla SEO .
Breadcrumb to typ znaczników, który pomaga tworzyć wyniki z elementami rozszerzonymi w wyszukiwaniu, pokazując ścieżkę do strony w strukturze Twojej witryny. Breadcrumbs pojawiają się dzięki odpowiedniemu linkowaniu, zoptymalizowanym kotwicom na linkach wewnętrznych i poprawnie zaimplementowanym ustrukturyzowanym danym (tym ostatnim zajmiemy się kilka akapitów poniżej).

W rzeczywistości linkowanie wewnętrzne może wpłynąć na ranking Twojej witryny i sposób, w jaki każda strona jest prezentowana w wynikach wyszukiwania. Aby dowiedzieć się więcej, zapoznaj się z naszym przewodnikiem SEO dotyczącym strategii linkowania wewnętrznego .
Szybkość witryny i wrażenia ze strony mają bezpośredni wpływ na pozycje organiczne. Odpowiedź serwera może stanowić problem z wydajnością witryny, gdy jednocześnie odwiedza ją zbyt wielu użytkowników. Jeśli chodzi o szybkość strony, Google oczekuje, że największa zawartość strony zostanie załadowana w widocznym obszarze w ciągu 2,5 sekundy lub mniej, i ostatecznie nagradza strony, które osiągają lepsze wyniki. Dlatego prędkość powinna być testowana i poprawiana zarówno po stronie serwera, jak i klienta.
Testy szybkości ładowania wykrywają problemy po stronie serwera, gdy zbyt wielu użytkowników jednocześnie odwiedza witrynę. Chociaż problem jest związany z ustawieniami serwera, SEO powinni wziąć to pod uwagę przed planowaniem kampanii SEO i reklamowych na dużą skalę. Przetestuj maksymalne obciążenie serwera, jeśli spodziewasz się gwałtownego wzrostu liczby odwiedzających. Zwróć uwagę na korelację między wzrostem liczby odwiedzających a czasem odpowiedzi serwera. Istnieją narzędzia do testowania obciążenia , które pozwalają symulować liczne rozproszone wizyty i testować wydajność serwera.
Po stronie serwera jedną z najważniejszych metryk jest pomiar TTFB , czyli czas do pierwszego bajtu . TTFB mierzy czas od wysłania żądania HTTP przez użytkownika do otrzymania pierwszego bajtu strony przez przeglądarkę klienta. Czas odpowiedzi serwera wpływa na wydajność Twoich stron internetowych. Audyt TTFB kończy się niepowodzeniem, jeśli przeglądarka czeka na odpowiedź serwera dłużej niż 600 ms. Pamiętaj, że najłatwiejszym sposobem na poprawę TTFB jest przejście z hostingu współdzielonego na hosting zarządzany , ponieważ w tym przypadku będziesz mieć serwer dedykowany tylko dla swojej witryny.
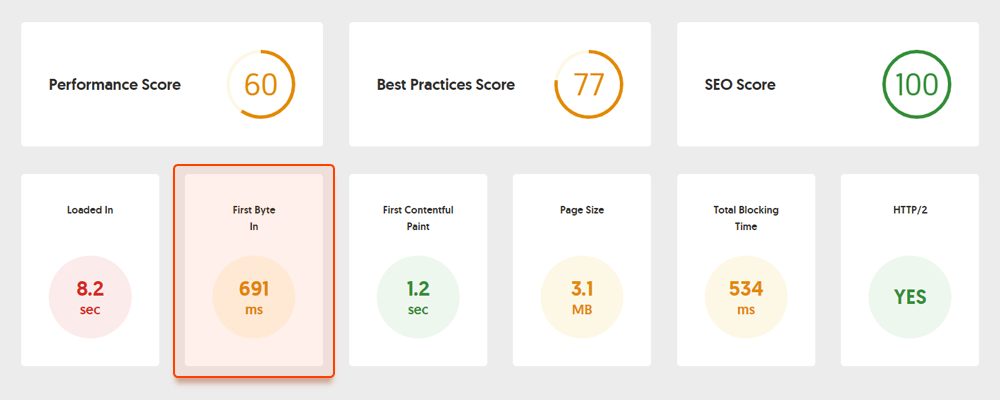
Oto na przykład test strony wykonany za pomocą Geekflare — bezpłatnego narzędzia do sprawdzania wydajności witryny . Jak widać narzędzie pokazuje, że TTFB dla tej strony przekracza 600ms, więc należy to poprawić.

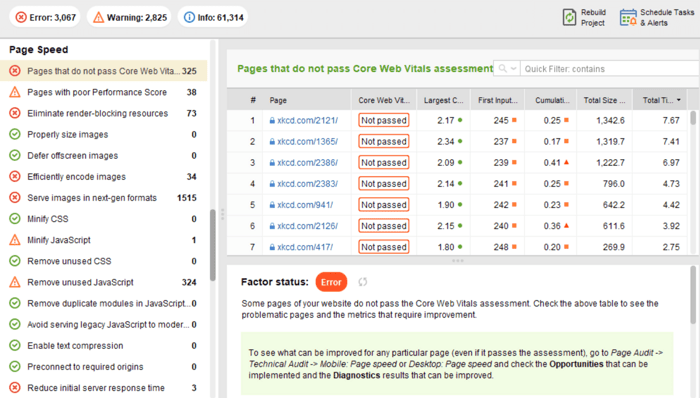
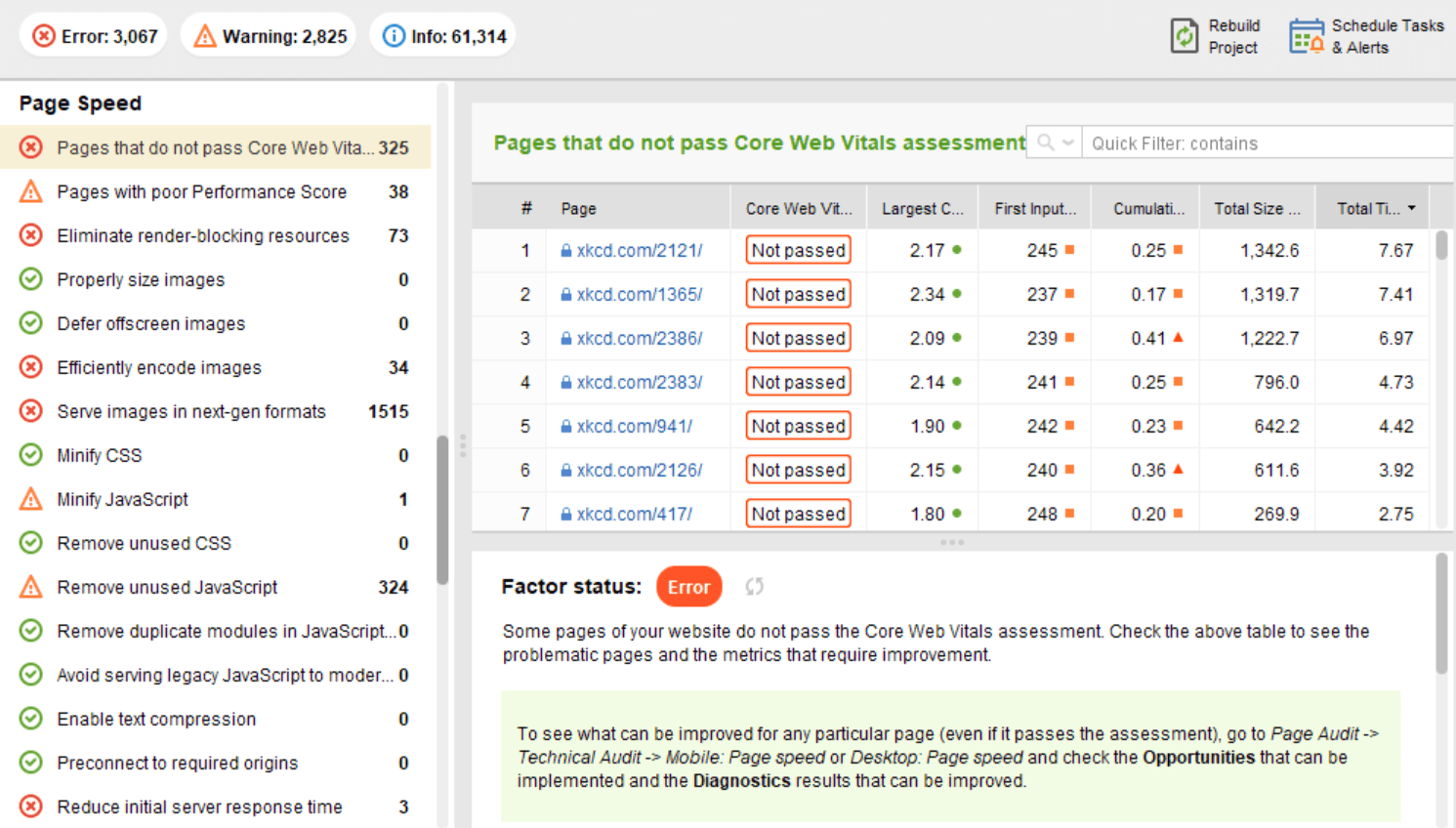
Jednak po stronie klienta szybkość strony nie jest łatwa do zmierzenia, a Google zmaga się z tym wskaźnikiem od dłuższego czasu. W końcu dotarł do Core Web Vitals — trzech wskaźników zaprojektowanych do pomiaru postrzeganej szybkości dowolnej strony. Te wskaźniki to największy problem związany z zawartością (LCP), opóźnienie pierwszego wejścia (FID) i skumulowana zmiana układu (CLS). Pokazują wydajność strony internetowej pod względem szybkości ładowania, interaktywności i stabilności wizualnej jej stron internetowych. Jeśli potrzebujesz więcej informacji na temat każdego wskaźnika CWV, zapoznaj się z naszym przewodnikiem na temat podstawowych wskaźników internetowych .
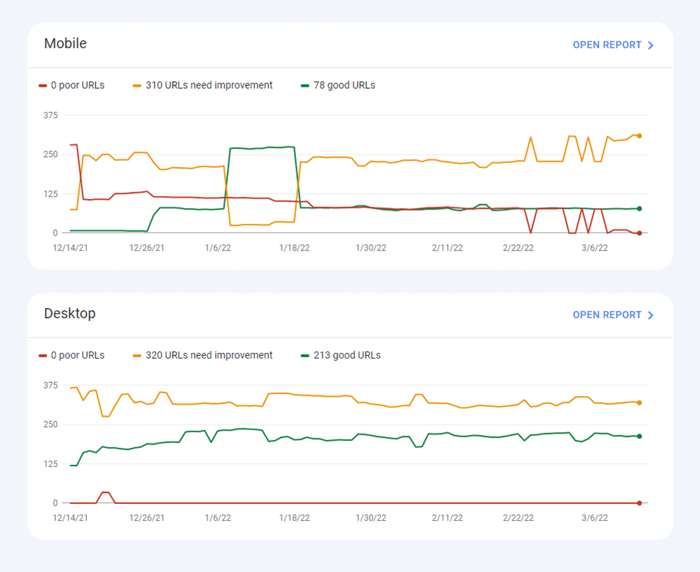
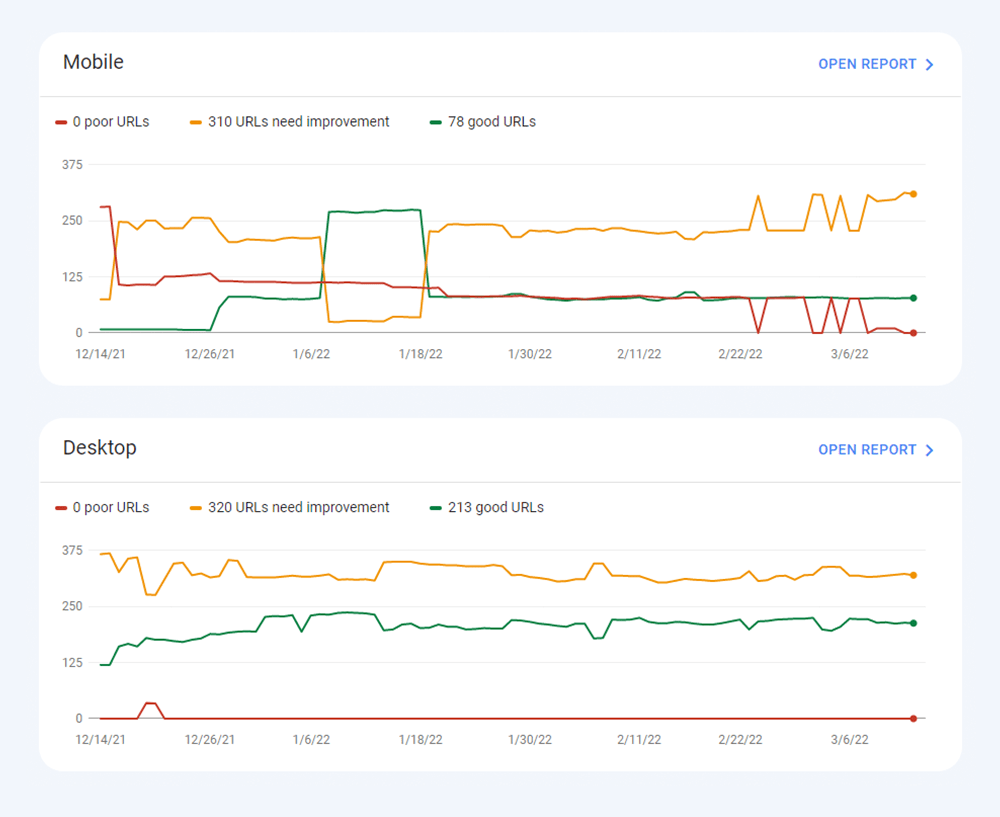
Ostatnio wszystkie trzy wskaźniki Core Web Vitalszostały dodane do WebSite Auditor . Tak więc, jeśli używasz tego narzędzia, możesz zobaczyć każdy wynik metryki, listę problemów z szybkością strony w Twojej witrynie oraz listę stron lub zasobów, których dotyczy problem. Dane są analizowane za pomocą klucza PageSpeed API , który można wygenerować bezpłatnie.
Zaletą korzystania z WebSite Auditor do audytu CWV jest to, że przeprowadzasz kontrolę zbiorczą dla wszystkich stron jednocześnie. Jeśli widzisz wiele stron, których dotyczy ten sam problem, prawdopodobnie problem dotyczy całej witryny i można go rozwiązać za pomocą jednej poprawki. Więc w rzeczywistości nie jest to tak dużo pracy, jak się wydaje. Wszystko, co musisz zrobić, to postępować zgodnie z zaleceniami po prawej stronie, a prędkość Twojej strony wzrośnie w mgnieniu oka.
Obecnie liczba wyszukiwarek mobilnych przewyższa te z komputerów stacjonarnych. W 2019 roku Google wdrożyło indeksowanie zorientowane na urządzenia mobilne , w ramach którego agent smartfonów indeksował strony internetowe przed komputerowym Googlebotem. Tak więc przyjazność dla urządzeń mobilnych ma ogromne znaczenie dla rankingów organicznych.
Co ciekawe, istnieją różne podejścia do tworzenia witryn przyjaznych urządzeniom mobilnym:
Zalety i wady każdego rozwiązania wyjaśniono w naszym szczegółowym przewodniku, jak dostosować witrynę do urządzeń mobilnych . Ponadto możesz odświeżyć strony AMP — chociaż nie jest to najnowocześniejsza technologia, nadal dobrze sprawdza się w przypadku niektórych typów stron, np. wiadomości.
Przyjazność dla urządzeń mobilnych pozostaje istotnym czynnikiem w przypadku witryn obsługujących jeden adres URL zarówno dla komputerów stacjonarnych, jak i telefonów komórkowych. Poza tym niektóre sygnały dotyczące użyteczności, takie jak brak natrętnych reklam pełnoekranowych, pozostają istotnym czynnikiem wpływającym zarówno na rankingi komputerów, jak i urządzeń mobilnych. Dlatego twórcy stron internetowych powinni zapewnić najlepsze wrażenia użytkownika na wszystkich typach urządzeń.
Przeprowadzony przez Google test dostosowania do urządzeń mobilnych obejmuje wybrane kryteria użyteczności, takie jak konfiguracja widocznego obszaru, użycie wtyczek oraz rozmiar tekstu i elementów, które można kliknąć. Należy również pamiętać, że dostosowanie do urządzeń mobilnych jest oceniane na podstawie poszczególnych stron, więc każdą stronę docelową należy sprawdzać osobno, pojedynczo.
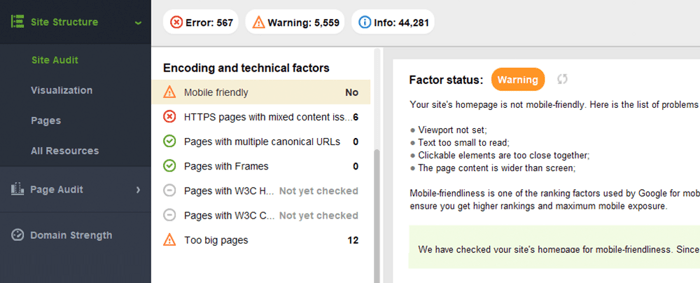
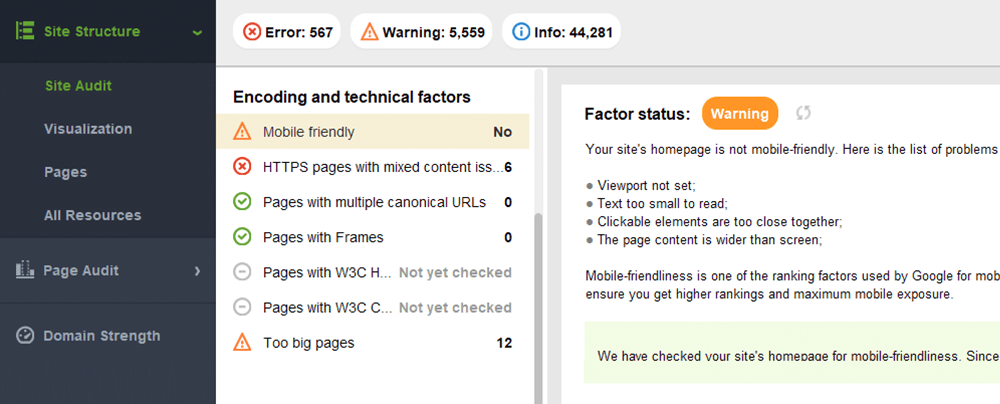
Aby ocenić całą witrynę, przełącz się na Google Search Console. Przejdź na kartę Jakość i kliknij raport Użyteczność mobilna , aby zobaczyć statystyki dla wszystkich swoich stron. Pod wykresem możesz zobaczyć tabelę z najczęstszymi problemami wpływającymi na Twoje strony mobilne. Klikając dowolny problem poniżej pulpitu nawigacyjnego, otrzymasz listę wszystkich adresów URL, których dotyczy problem.
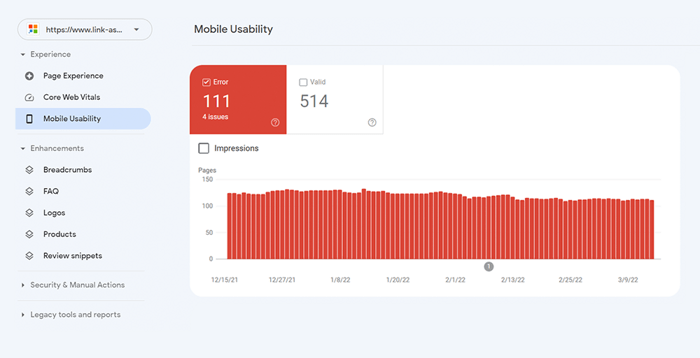

Typowe problemy związane z dostosowaniem do urządzeń mobilnych to:
WebSite Auditor sprawdza również, czy strona główna jest dostosowana do urządzeń mobilnych i wskazuje problemy związane z komfortem użytkowników mobilnych. Przejdź do Audyt witryny > Kodowanie i czynniki techniczne . Narzędzie pokaże, czy witryna jest dostosowana do urządzeń mobilnych, i wyświetli listę ewentualnych problemów:
Sygnały na stronie są bezpośrednimi czynnikami rankingowymi i bez względu na to, jak dobra jest techniczna solidność Twojej witryny, Twoje strony nigdy nie pojawią się w wynikach wyszukiwania bez odpowiedniej optymalizacji tagów HTML . Twoim celem jest sprawdzenie i uporządkowanie tytułów, metaopisów i nagłówków H1–H3 treści w witrynie.
Tytuł i metaopis są używane przez wyszukiwarki do tworzenia fragmentu wyniku wyszukiwania. Ten fragment jest tym, co użytkownicy zobaczą jako pierwsze, dlatego ma duży wpływ na organiczny współczynnik klikalności .
Nagłówki wraz z akapitami, listami wypunktowanymi i innymi elementami struktury strony pomagają tworzyć bogate wyniki wyszukiwania w Google. Ponadto w naturalny sposób poprawiają czytelność i interakcję użytkownika ze stroną, co może być pozytywnym sygnałem dla wyszukiwarek. Miej oko na:
Duplikuj tytuły, nagłówki i opisy w całej witrynie — popraw je, pisząc unikalne dla każdej strony.
Optymalizacja tytułów, nagłówków i opisów dla wyszukiwarek (tj. długość, słowa kluczowe itp.)
Niska zawartość — strony z niewielką zawartością prawie nigdy nie uzyskają pozycji w rankingu, a nawet mogą zepsuć autorytet witryny (z powodu algorytmu Panda), więc upewnij się, że Twoje strony dogłębnie omawiają ten temat.
Optymalizacja obrazów i plików multimedialnych — korzystaj z formatów przyjaznych dla SEO, stosuj leniwe ładowanie, zmieniaj rozmiar plików, aby były lżejsze itp. Aby uzyskać więcej informacji, przeczytaj nasz przewodnik dotyczący optymalizacji obrazów .
WebSite Auditor może ci bardzo pomóc w tym zadaniu. Sekcja Struktura witryny > Audyt witryny umożliwia zbiorcze sprawdzanie problemów z metatagami w całej witrynie. Jeśli potrzebujesz bardziej szczegółowego audytu zawartości poszczególnych stron, przejdź do sekcji Audyt strony . Aplikacja ma również wbudowane narzędzie do pisania Content Editor , które oferuje sugestie dotyczące ponownego pisania stron w oparciu o najlepszych konkurentów SERP. Możesz edytować strony w ruchu lub pobrać rekomendacje jako zadanie dla copywriterów.
Aby uzyskać więcej informacji, przeczytaj nasz przewodnik po optymalizacji SEO na stronie .
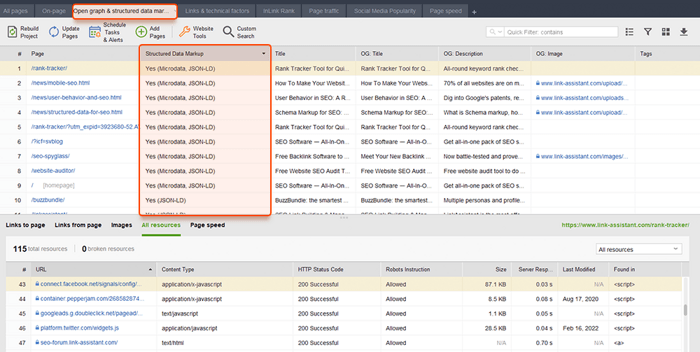
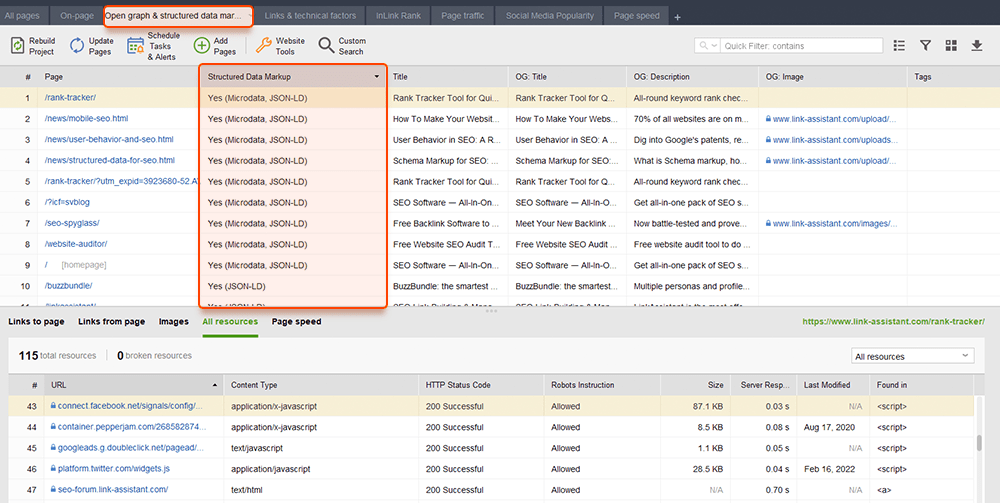
Dane strukturalne to znaczniki semantyczne, które pozwalają robotom wyszukującym lepiej zrozumieć zawartość strony. Na przykład, jeśli Twoja strona zawiera przepis na szarlotkę, możesz użyć danych strukturalnych, aby powiedzieć Google, który tekst zawiera składniki, czyli czas gotowania, liczbę kalorii i tak dalej. Google używa znaczników do tworzenia rozszerzonych fragmentów dla twoich stron w SERP.
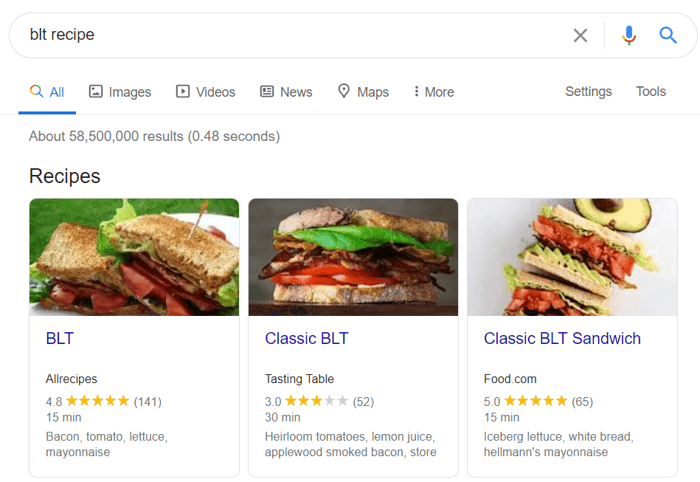
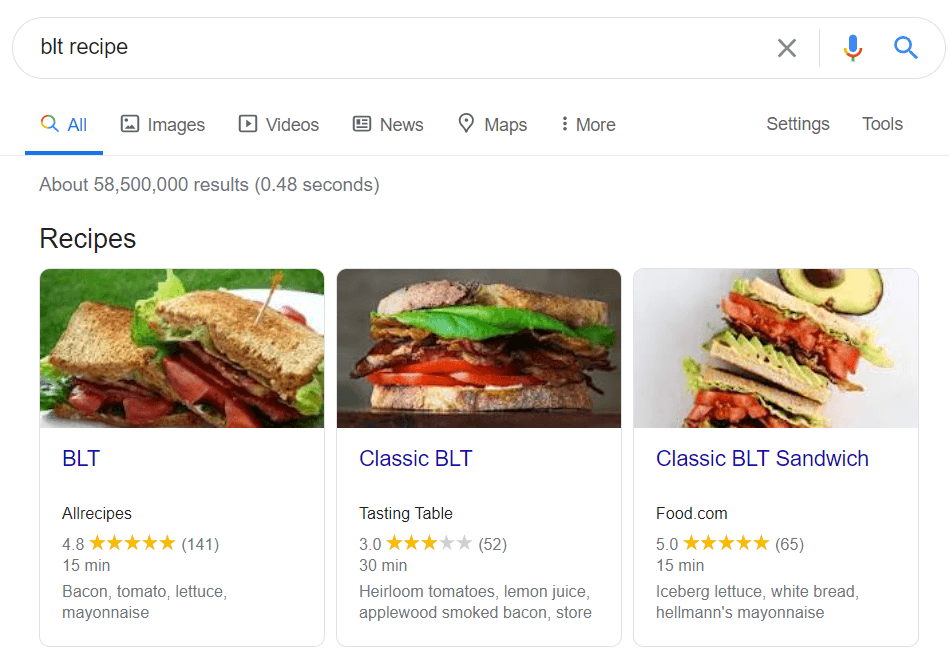
Istnieją dwa popularne standardy uporządkowanych danych: OpenGraph do pięknego udostępniania w mediach społecznościowych oraz Schema do wyszukiwarek. Warianty implementacji znaczników to: Microdata, RDFa i JSON-LD . Mikrodane i RDFa są dodawane do kodu HTML strony, natomiast JSON-LD to kod JavaScript. Ten ostatni jest zalecany przez Google.
Jeśli typ zawartości Twojej strony jest jednym z wymienionych poniżej, znaczniki są szczególnie zalecane:
Pamiętaj, że manipulowanie danymi strukturalnymi może spowodować kary ze strony wyszukiwarek. Na przykład znaczniki nie powinny opisywać treści, które są ukryte przed użytkownikami (tj. które nie znajdują się w kodzie HTML strony). Przed wdrożeniem przetestuj swoje znaczniki za pomocą Narzędzia do testowania danych strukturalnych .
Możesz również sprawdzić swoje znaczniki w Google Search Console na karcie Ulepszenia . GSC wyświetli ulepszenia, które próbowałeś zaimplementować w swojej witrynie i poinformuje Cię, czy Ci się udało.
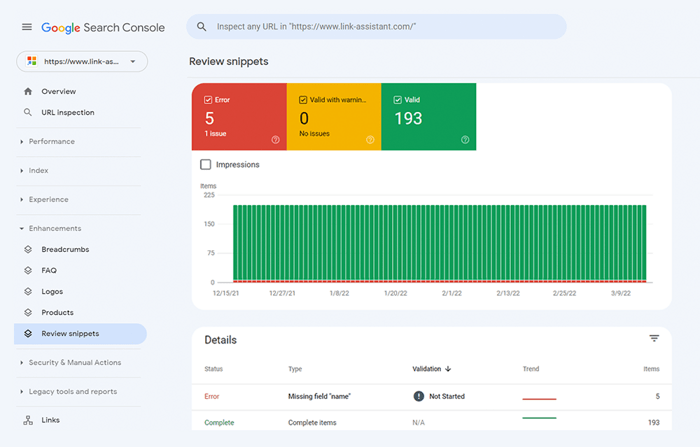
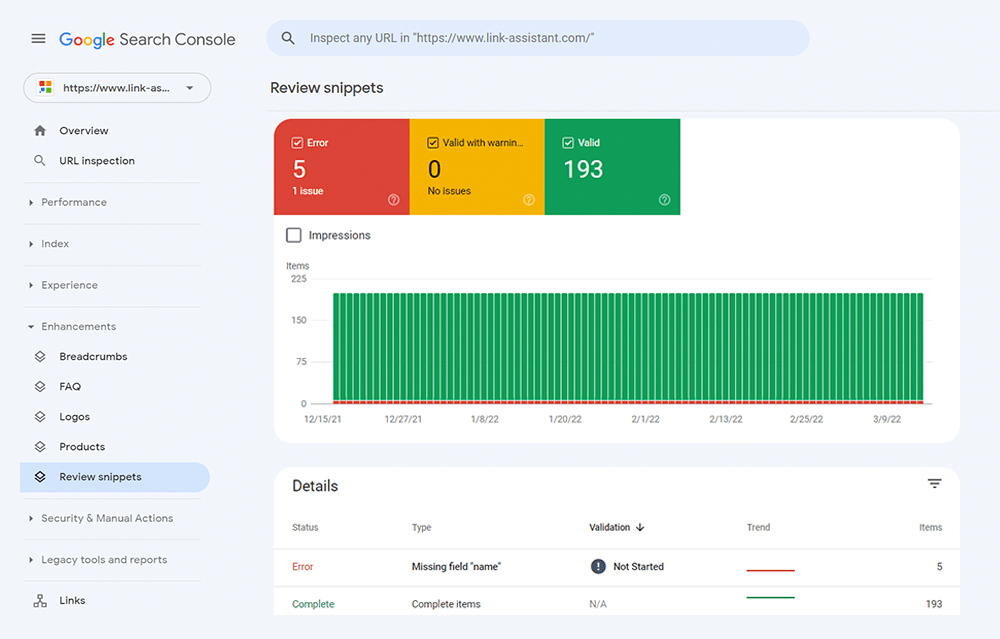
WebSite Auditor może również pomóc tutaj. Narzędzie może przejrzeć wszystkie Twoje strony i pokazać obecność danych strukturalnych na stronie, ich typ, tytuły, opisy i adresy URL plików OpenGraph.
Jeśli jeszcze nie zaimplementowałeś znaczników schematu, zapoznaj się z tym przewodnikiem SEO dotyczącym danych strukturalnych . Pamiętaj, że jeśli Twoja witryna korzysta z systemu CMS, dane strukturalne mogą być domyślnie zaimplementowane lub możesz je dodać, instalując wtyczkę (i tak nie przesadzaj z wtyczkami).
Po przeprowadzeniu audytu witryny i naprawieniu wszystkich wykrytych problemów możesz poprosić Google o ponowne zindeksowanie Twoich stron, aby szybciej zobaczyło zmiany.
W Google Search Console prześlij zaktualizowany adres URL do narzędzia do sprawdzania adresów URL i kliknij Poproś o indeksowanie . Możesz także skorzystać z funkcji Testuj aktywny adres URL (wcześniej znanej jako funkcja Pobierz jako Google ), aby zobaczyć swoją stronę w jej obecnej formie, a następnie poprosić o zindeksowanie.
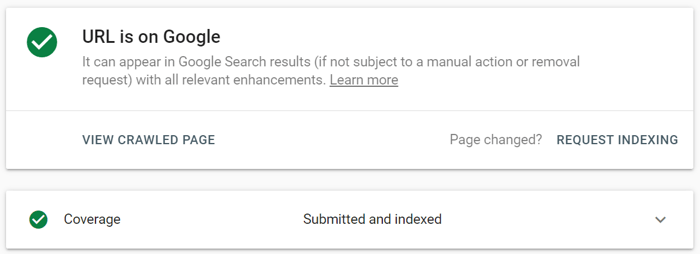
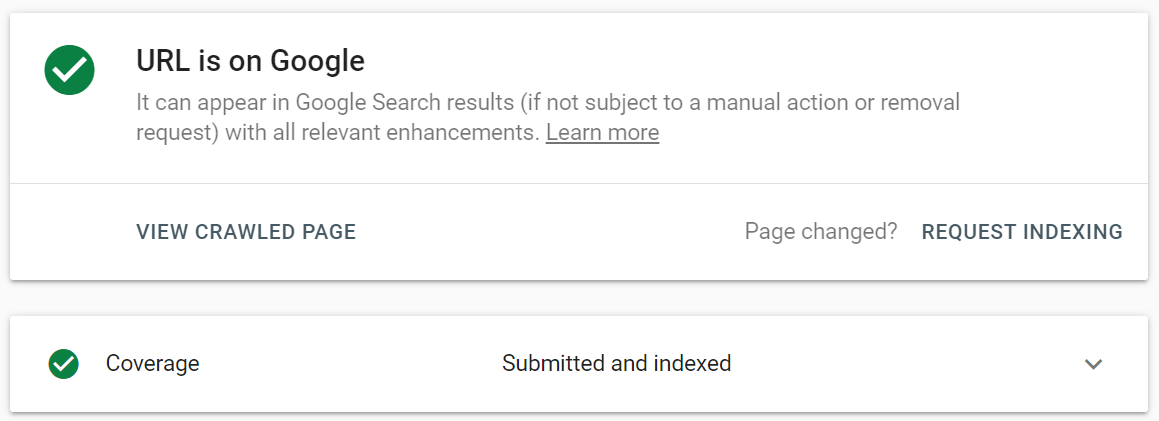
Narzędzie do inspekcji adresów URL umożliwia rozszerzenie raportu o więcej szczegółów, testowanie aktywnych adresów URL i żądanie indeksowania.
Pamiętaj, że nie musisz wymuszać ponownego indeksowania za każdym razem, gdy coś zmienisz w swojej witrynie. Rozważ ponowne zindeksowanie, jeśli zmiany są poważne: powiedzmy, że przeniosłeś swoją witrynę z http na https, dodałeś dane strukturalne lub dokonałeś świetnej optymalizacji treści, opublikowałeś pilny post na blogu, który chcesz szybciej pojawić się w Google itp. Pamiętaj, że Google ma limit od liczby operacji ponownego indeksowania w miesiącu, więc nie nadużywaj tego. Co więcej, większość CMS przesyła wszelkie zmiany do Google, gdy tylko je wprowadzisz, więc możesz nie zawracać sobie głowy ponownym indeksowaniem, jeśli korzystasz z CMS (takiego jak Shopify lub WordPress).
Ponowne indeksowanie może zająć od kilku dni do kilku tygodni, w zależności od tego, jak często robot odwiedza strony. Wielokrotne żądanie ponownego indeksowania nie przyspieszy tego procesu. Jeśli musisz ponownie zindeksować ogromną liczbę adresów URL, prześlij mapę witryny zamiast ręcznie dodawać każdy adres URL do narzędzia do sprawdzania adresów URL.
Ta sama opcja jest dostępna w Narzędziach dla webmasterów Bing. Po prostu wybierz sekcję Konfiguruj moją witrynę na pulpicie nawigacyjnym i kliknij Prześlij adresy URL . Wpisz adres URL, który chcesz ponownie zindeksować, a Bing zindeksuje go w ciągu kilku minut. Narzędzie umożliwia webmasterom przesyłanie do 10 000 adresów URL dziennie dla większości witryn.
W sieci może się wydarzyć wiele rzeczy, a większość z nich może mieć lepszy lub gorszy wpływ na Twoje rankingi. Dlatego regularne audyty techniczne Twojej witryny powinny być istotną częścią Twojej strategii SEO.
Na przykład możesz zautomatyzować techniczne audyty SEO w WebSite Auditor . Po prostu utwórz zadanie Odbuduj projekt i ustaw ustawienia harmonogramu (powiedzmy raz w miesiącu), aby Twoja witryna była automatycznie ponownie indeksowana przez narzędzie i pobierała świeże dane.
Jeśli chcesz udostępnić wyniki audytu swoim klientom lub współpracownikom, wybierz jeden z dostępnych do pobrania szablonów raportów SEO WebSite Auditor lub utwórz własny.
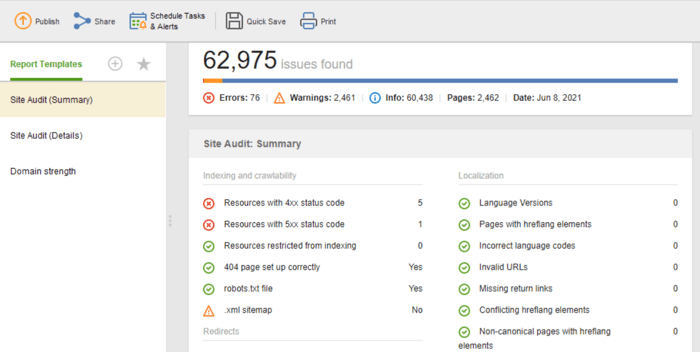
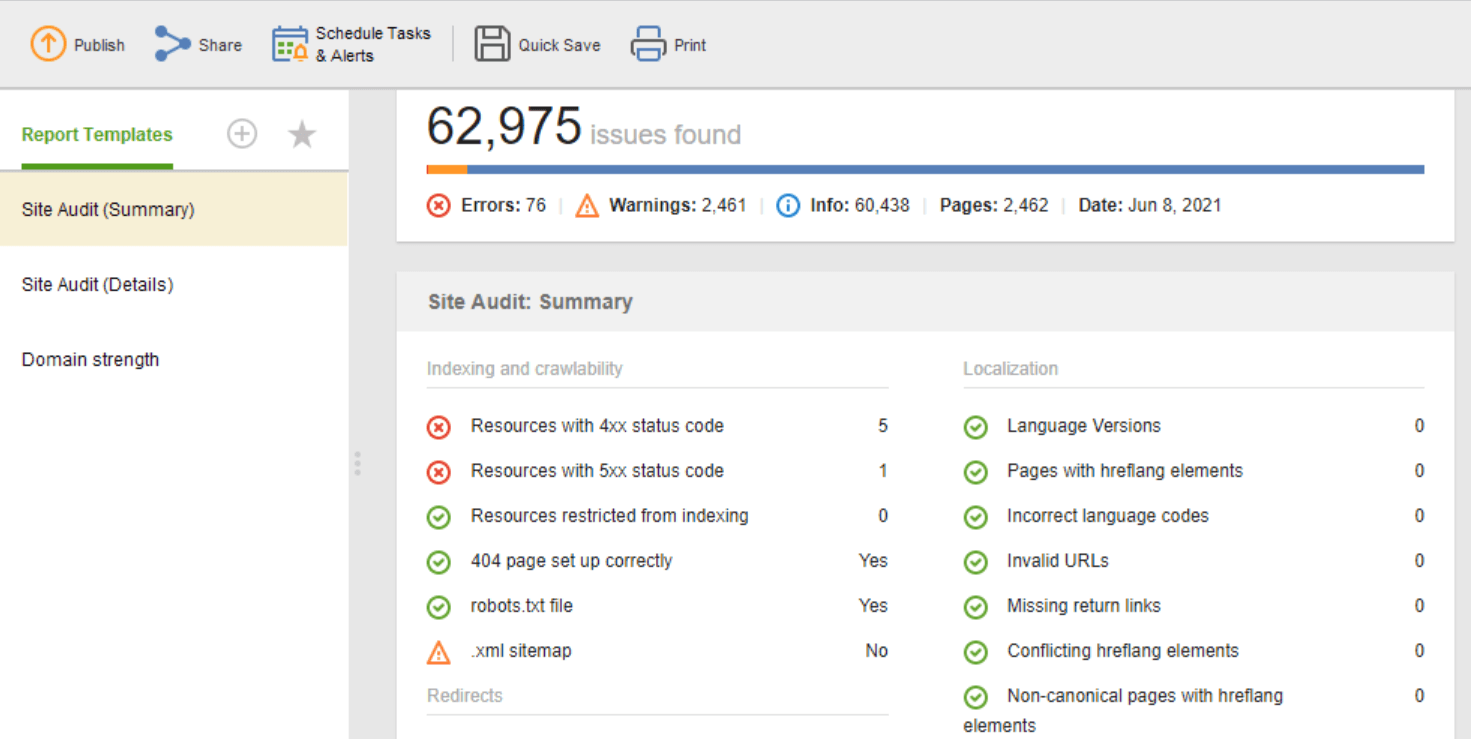
Szablon audytu witryny (podsumowanie) jest świetny dla redaktorów stron internetowych, aby zobaczyć zakres prac optymalizacyjnych do wykonania. Szablon audytu witryny (szczegóły) jest bardziej przejrzysty i zawiera opis każdego problemu oraz wyjaśnienie, dlaczego ważne jest, aby go naprawić. W Website Auditor możesz dostosować raport z audytu witryny, aby uzyskać dane, które musisz regularnie monitorować (indeksowanie, zepsute linki, na stronie itp.). Następnie wyeksportuj jako plik CSV/PDF lub skopiuj dowolne dane do arkusza kalkulacyjnego, aby mieć je pod ręką to do programistów do poprawek.
Co więcej, możesz uzyskać pełną listę technicznych problemów SEO na dowolnej stronie internetowej zebraną automatycznie w raporcie z audytu witryny w naszym WebSite Auditor. Ponadto szczegółowy raport zawiera wyjaśnienia dotyczące każdego problemu i sposobu jego rozwiązania.
Są to podstawowe kroki regularnego audytu technicznego witryny. Mam nadzieję, że poradnik najlepiej opisuje, jakich narzędzi potrzebujesz, aby przeprowadzić dokładny audyt strony, na jakie aspekty SEO zwrócić uwagę i jakie środki zapobiegawcze podjąć, aby utrzymać dobrą kondycję SEO Twojej witryny.
Co to jest techniczne SEO?
Techniczne SEO zajmuje się optymalizacją technicznych aspektów strony internetowej, które pomagają robotom wyszukiwawczym skuteczniej uzyskiwać dostęp do Twoich stron. Techniczne SEO obejmuje indeksowanie, indeksowanie, problemy po stronie serwera, doświadczenie strony, generowanie metatagów, strukturę witryny.
Jak przeprowadzić techniczny audyt SEO?
Techniczny audyt SEO zaczyna się od zebrania wszystkich adresów URL i analizy ogólnej struktury Twojej witryny. Następnie sprawdzasz dostępność stron, szybkość ładowania, tagi, szczegóły na stronie itp. Techniczne narzędzia do audytu SEO obejmują zarówno bezpłatne narzędzia dla webmasterów, jak i pająki SEO, analizatory plików dziennika itp.
Kiedy muszę przeprowadzić audyt witryny?
Techniczne audyty SEO mogą mieć różne cele. Możesz chcieć przeprowadzić audyt strony internetowej przed uruchomieniem lub w trakcie trwającego procesu optymalizacji. W innych przypadkach możesz przeprowadzać migracje witryn lub chcieć znieść sankcje Google. W każdym przypadku zakres i metody audytów technicznych będą się różnić.


| Linking websites | N/A |
| Backlinks | N/A |
| InLink Rank | N/A |